Rearranging the abstraction layers
A common situation
If you ever wrote software that had to interact with a database, you might have used this very common pattern:
- Your program needs data to perform its duties
- Data happens to be stored in a database
- There's a middle layer that handles the dialogue with the database, abstracts away the details of dealing with "raw" data, and enforces any business logic rule that may not be conveniently representd in the database
The advantages of having a middle layer are many. It simplifies a switch in the specific database system
Your program is supposed to never access the database directly. Doing so is (correctly) considered a bad practice, because it violates the separation of concerns principle and might have a number of unpleasant consequences with future developments.
So far, I don't think I described something new.
Still, there's something in this scenario I'm not quite satisfied with.
But abstracting away the database also means abstracting away the language used to talk about data and to express questions about data.
It's true we are not supposed to talk with the DB directly, but that should not imply we're not supposed to talk about data using a language suitable to do so.
For example, let's say there's a employee table in the database:
| employee |
|---|
| name |
| position |
| salary |
There's also a get_all_employees method in the API, returning an
array of objects. Our task is to compute the total salary paid by the
company for its management. Using a pseudolanguage:
employees = api.get_all_employees;
total_salary = 0;
foreach e in employees {
next if e.position == 'Manager';
total_salary += e.salary;
}
Whereas, with access to the database, this piece of code would be as simple as:
select sum(salary) from employees where position = 'Manager';
which I think it's more straightforward, more expressive (I mean the intent of the code is more apparent) and possibly more efficient, depending on how the database engine executes the query, but that's another story.
Another approach
Since we're not allowed to access the database, it seems we're bound to not being able to use SQL to express questions on data.
However, lately I've been using a different approach that, albeit not solving every issue I mentioned, leads to code that in my opinion is more clear. Here a depiction of the pattern:
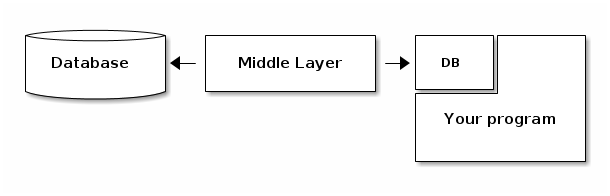
As before, your program needs data to perform its duties, there's a database and some API to access it, but this time there's another database at the application level.
Its purpose is to temporarily store data needed by the application.
Here the same example of the previous paragraph, using this technique.
local_db.init; employees = api.get_all_employees; local_db.load( employees ); total_salary = local_db.execute( "select sum(salary) from employees" );
In practice, I'm using sqlite as a temporary, in-memory db.
local_db represents a handler to talk with it. the init method
prepares the tables we're going to need to handle our copy of the
data. load method loads the data we need later.
Finally, we can use SQL to access our local copy of the data.
Problems
- I'm basically using a glorified big global variable; I can't use this technique in persistent environments
- Changes in data (at the main db level) that occur after the
loadmethod invocation are not taken into account
Other ideas
- I started this article talking about databases, ending up with a technique that in some cases might be convenient to handle data structures. But the point of this tecnique is using the right language to express queries on data, so you can use it in a much broader context
- Instead of memory, you can use a file to store the db. This is useful for debugging: after your program run you still have a copy of the db you can interact with using the sqlite client