hledger-dupes
Update
- hledger-dupes is now included in hledger.
Using hledger
originally published in January 2015. You can find the complete source code in its github repository
Last year I was disciplined enough to manage my expenses using hledger, an accounting program written in Haskell. The results are scary and very useful at the same time: scary because I didn't know I spend so much in certain categories of items, useful because with this data in hand I can optimize how I use my money.
One of the benefits of using hledger is that, besides the functionality immediately available, one can develop other utilities using the library the software is based on, hledger-lib.
One problem I have is that I sometimes write account names in different ways while I record expenses.
For example, let's say I buy a bottle of wine to bring to a dinner party:
03/10 expenses:wine €12.00 assets:cash
Later, I buy another bottle but while recording it among other shoppings I erroneously categorize it as food:
10/17 expenses:food:wine €12.00 assets:cash
The error in this case is particularly evident exploring the account tree with hledger-web. But if you have hundreds, as it's customary using hledger, such an error can slip easily.
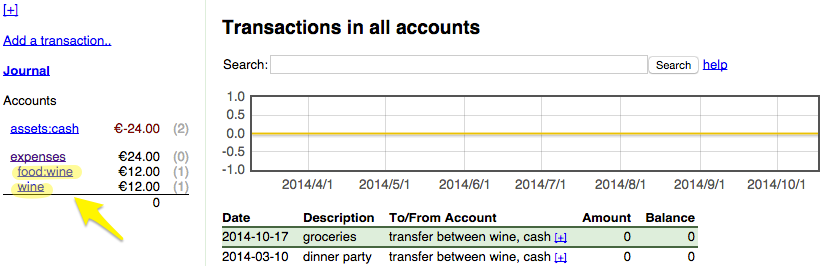
What I'd like to have is a tool that automatically spot duplicates in the account tree: duplicates are defined as account names having the same leaf but different prefixes. In other words, two or more leaves that are categorized differently.
The code
I didn't find much documentation for hledger-lib, but reading (or stealing) the code from the implementation of hledger was enough for my purposes.
First we need a list of every account:
accountsNames :: Journal -> [(String, AccountName)] accountsNames j = map leafAndAccountName as where leafAndAccountName a = (accountLeafName a, a) ps = journalPostings j as = nub $ sort $ map paccount ps
This is a simplified version of the accounts command as it is
implemented for hledger. Note I don't want only a simple list of
accounts, but a list of tuples where the first element is the leaf name
- a
String-, the second one is the complete name for the account,
expressed as AccountName (a type defined in Hledger). This will be
essential later, to decide what a duplicate is.
Following the wine example, here the list accountsNames would return:
[("wine", "expenses:wine"), ("wine", "expenses:food:wine")]
Now, we need to compute the list of duplicates. Let's first focus on the core of the function: according to me is the more interesting and elegant part of the program (no wonder is largely not by me, but adapted from code I found in a post by Neil Mitchell, "Repeated Word Detection with Haskell").
This function takes a list of tuples and returns a new list of tuples that are duplicates.
dupes' = filter ((> 1) . length) . groupBy ((==) `on` fst) . sortBy (compare `on` fst)
It is written in the so-called pointfree style, without mentioning the points (the data) is will operate on, just combining other simpler functions.
First it sorts the list of tuples according to their fst element, then
it groups to tuples according to a special notion of equality
((=) `on` fst=, i.e. two accounts are considered equal if their leaf
name is equal), and eventually returns the groups that have more than
one elements.
This function is embedded in a more complex one, suitable to obtain the
data structure we need for the final output. Now I need to specify two
type constraints (Ord and Eq) for the first elements of the tuples.
dupes :: (Ord k, Eq k) => [(k, v)] -> [(k, [v])] dupes l = zip dupLeafs dupAccountNames where dupLeafs = map (fst . head) d dupAccountNames = map (map snd) d d = dupes' l dupes' = filter ((> 1) . length) . groupBy ((==) `on` fst) . sortBy (compare `on` fst)
An example of the result:
[("wine", ["expenses:wine", "expenses:food:wine"])]
We're close. We just need a function to print useful information about the duplicates.
render :: (String, [AccountName]) -> IO () render (leafName, accountNameL) = printf "%s as %s\n" leafName (concat $ intersperse ", " accountNameL)
And the main function:
main = do args <- getArgs deffile <- defaultJournalPath let file = headDef deffile args j <- readJournalFile Nothing Nothing file >>= either error' return mapM_ render $ dupes $ accountsNames j
Here the final output for the test journal I wrote at the beginning.
$ ./hledger-dupes test.journal wine as expenses:food:wine, expenses:wine