Posts tagged "meta":




Emacs config size
Let’s Play How Big Is Your Emacs Config?
In my case:
wc -l .emacs.d/lisp/larsen-* .emacs.d/init.el | ag total
2400 total
Also
A dedicated blog instance for links
I decided to separate normal posts and links posts into two separate blog instances: blog and linkage.
Managing multiple blog instances with org-static-blog
By itself, org-static-blog does not support multiple blog instances, but it's quite easy to obtain a similar feature.
(defvar +my-blogs+
'((blog . ((org-static-blog-publish-title . "Stefano Rodighiero — Stream")
(org-static-blog-publish-url . "https://stefanorodighiero.net/blog/")
;; ... and so on ...
))
(linkage . ((org-static-blog-publish-title . "Stefano Rodighiero — Linkage")
(org-static-blog-publish-url . "https://stefanorodighiero.net/linkage/")
;; ... and so on ...
))))
(defun select-active-blog (blog-name)
(interactive (list (intern (completing-read "Select active blog for publication: "
(mapcar #'car +my-blogs+)))))
(let ((blog-options (cdr (assoc blog-name +my-blogs+))))
(message "Setting active blog: %s" blog-name)
(dolist (option-name (mapcar #'car blog-options))
(set option-name (cdr (assoc option-name blog-options))))))
Then org-static-blog functions can be advised so that select-active-blog is called before the operations.
(advice-add 'org-static-blog-publish :before (lambda (&rest args)
(call-interactively 'select-active-blog)))
My Emacs configuration changes in 2025
$ git diff tags/2024...tags/2025 --stat | ag changed 38 files changed, 540 insertions(+), 409 deletions(-)
A list of the main changes (introducing or eliminating packages, structural changes, important changes in the interface).
0441b30 |
2025-01-04 | dired-subtree configuration |
4fc34aa |
2025-02-04 | switch to doom-tomorrow-night as default |
3100c81 |
2025-02-05 | + forge |
90dfc96 |
2025-02-05 | + org-sidebar |
5318eb6 |
2025-02-16 | switch to sqlformat |
6eddac8 |
2025-02-16 | + vertico + corfu + marginalia + orderless + consult |
291089c |
2025-02-16 | combo for consult-line |
0de118b |
2025-02-21 | trying treesit-fold instead of yafolding |
e54719f |
2025-02-21 | sideline + minimap (WIP) |
a030077 |
2025-03-07 | + colorful package |
bf09612 |
2025-03-08 | using hideshow instead of treesit-fold, more versatile |
801fddf |
2025-03-15 | git in fringes |
d91e87d |
2025-03-15 | Personalized fringe bitmap for Flymake |
1e56038 |
2025-03-15 | Integration with Ollama (Ellama) |
169efab |
2025-06-15 | minimal init messages |
f42b4b6 |
2025-06-20 | Jira integration (using auth-info) |
9000572 |
2025-09-17 | renamed larsen-ibuffer -> larsen-buffer; added bufferlo package |
eedc448 |
2025-09-19 | better configuration for the background |
4db8195 |
2025-10-08 | new work projects agenda view |
2c0cb99 |
2025-11-20 | Switch to Sly (from Slime) |
d65d153 |
2025-11-20 | more adjustments for Sly |
147e53c |
2025-11-20 | + embark |
1123bd1 |
2025-11-20 | setup for using and exporting GPX files |
8f2db38 |
2025-12-30 | extending image-dired to show image size |
Books read in 2025
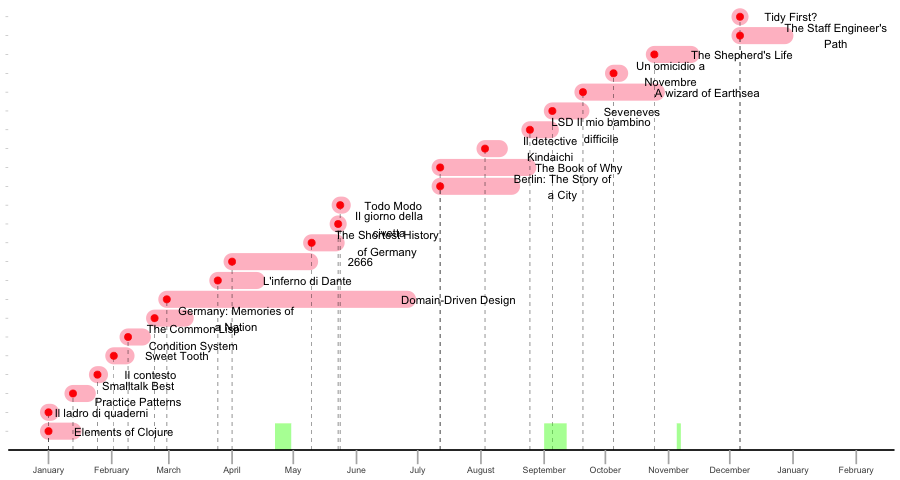
| Author | Title | Pages | Started | Finished | Category | |
|---|---|---|---|---|---|---|
| Zachary Tellman | ⭐ | Elements of Clojure | 119 | 2025-01-01 | 2025-01-13 | N |
| Gianni Solla | Il ladro di quaderni | 256 | 2025-01-01 | 2025-01-02 | F | |
| Kent Beck | ⭐ | Smalltalk Best Practice Patterns | 215 | 2025-01-13 | 2025-01-20 | N |
| Leonardo Sciascia | Il contesto | 114 | 2025-01-25 | 2025-01-26 | F | |
| Ian McEwan | Sweet Tooth | 370 | 2025-02-02 | 2025-02-08 | F | |
| Michał "phoe" Herda | The Common Lisp Condition System | 320 | 2025-02-09 | 2025-02-16 | N | |
| Neil MacGregor | Germany: Memories of a Nation | 563 | 2025-02-22 | 2025-03-09 | N | |
| Eric Evans | ⭐ | Domain-Driven Design | 560 | 2025-02-28 | 2025-06-26 | N |
| Vittorio Sermonti | L'inferno di Dante | 555 | 2025-03-25 | 2025-04-13 | N | |
| Roberto Bolaño | ⭐ | 2666 | 963 | 2025-04-01 | 2025-05-09 | F |
| James Hawes | The Shortest History of Germany | 227 | 2025-05-10 | 2025-05-22 | N | |
| Leonardo Sciascia | Il giorno della civetta | 137 | 2025-05-23 | 2025-05-23 | F | |
| Leonardo Sciascia | Todo Modo | 121 | 2025-05-24 | 2025-05-25 | F | |
| Judea Pearl, Dana Mackenzie | ⭐ | The Book of Why | 372 | 2025-07-12 | 2025-08-24 | N |
| Barney White-Spunner | ⭐ | Berlin: The Story of a City | 448 | 2025-07-12 | 2025-08-16 | N |
| Seishi Yokomizo | Il detective Kindaichi | 145 | 2025-08-03 | 2025-08-10 | F | |
| Albert Hofmann | LSD Il mio bambino difficile | 175 | 2025-08-25 | 2025-09-04 | N | |
| Neal Stephenson | Seveneves | 861 | 2025-09-05 | 2025-09-19 | F | |
| Simon Masoned | Un omicidio a Novembre | 382 | 2025-10-05 | 2025-10-08 | F | |
| Ursula K. Le Guin | A wizard of Earthsea | 167 | 2025-09-20 | 2025-10-26 | F | |
| James Rebanks | ⭐ | The Shepherd's Life | 287 | 2025-10-25 | 2025-11-12 | N |
| Kent Beck | Tidy First? | 92 | 2025-12-06 | 2025-12-06 | N | |
| Tanya Reilly | The Staff Engineer's Path | 311 | 2025-12-06 | 2025-12-28 | N | |
| 7760 |
(⭐ marks books I particularly liked)
Camping in Stendenitz
This wasn't a lucky season for bikepacking—bad weather, mechanical problems, and lack of time conspired against me. But I managed to catch a break this weekend. I chose a campsite almost at random (I just had a rough distance and direction in mind), but I hit the jackpot.
It was a beautiful, quiet place, and I was assigned a wonderful spot right in front of the lake. This will most likely be my last night out this year, but it was a great one.




Venetogravel 2025
Over the last weekend I partecipated to my second Venetogravel. This time following the Short Beach track, covering approximately 400 kilometers and 2200 meters of elevation. The weather in the first two day was not the best, but I still enjoyed it very much. Here some stats and a small selection of pictures
| Time in motion | Elapsed Time | ↔ | Avg speed | ↗ | ↘ | |
|---|---|---|---|---|---|---|
| 25/04 | 06:43 | 09:10 | 132 km | 19.6 km/h | 110 m | 190 m |
| 26/04 | 05:38 | 08:29 | 111 km | 19.7 km/h | 150 m | 120 m |
| 27/04 | 06:16 | 10:56 | 101 km | 16.2 km/h | 1,380 m | 1,220 m |
| 28/04 | 03:09 | 04:29 | 53.3 km | 16.9 km/h | 540 m | 640 m |




Books read in 2024
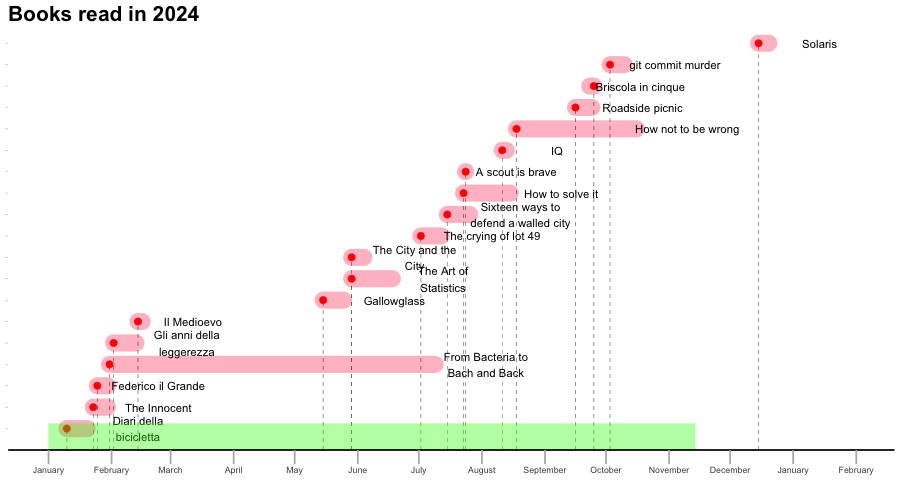
| Author | Title | Pages | Started | Finished | Category |
|---|---|---|---|---|---|
| David Byrne | Diari della bicicletta | 382 | 2024-01-10 | 2024-01-20 | N |
| Ian McEwan | The Innocent | 226 | 2024-01-23 | 2024-01-30 | F |
| Alessandro Barbero | Federico il Grande | 172 | 2024-01-25 | 2024-01-30 | N |
| Elizabeth Jane Howard | Gli anni della leggerezza | 600 | 2024-02-02 | 2024-02-13 | F |
| Jacques Le Goff | Il Medioevo | 126 | 2024-02-14 | 2024-02-16 | N |
| Daniel C. Dennett | From Bacteria to Bach and Back | 496 | 2024-01-31 | 2024-07-09 | N |
| S.J. Morden | Gallowglass | 373 | 2024-05-15 | 2024-05-25 | F |
| David Spiegelhalter | The Art of Statistics | 380 | 2024-05-29 | 2024-06-18 | N |
| China Miéville | The City and the City | 372 | 2024-05-29 | 2024-06-04 | F |
| Thomas Pynchon | The crying of lot 49 | 142 | 2024-07-02 | 2024-07-12 | F |
| K.J. Parker | Sixteen ways to defend a walled city | 350 | 2024-07-15 | 2024-07-26 | F |
| Will Ludwigsen | A scout is brave | 158 | 2024-07-24 | 2024-07-24 | F |
| George Polya | How to solve it | 253 | 2024-07-23 | 2024-08-15 | N |
| Joe Ide | IQ | 336 | 2024-08-11 | 2024-08-13 | F |
| Jordan Ellenberg | How not to be wrong | 437 | 2024-08-18 | 2024-10-16 | N |
| Arkady & Boris Strugatsky | Roadside picnic | 193 | 2024-09-16 | 2024-09-24 | F |
| Marco Malvaldi | Briscola in cinque | 163 | 2024-09-25 | 2024-09-23 | F |
| Michael Warren Douglas | git commit murder | 263 | 2024-10-03 | 2024-10-10 | F |
| Stanislaw Lem | Solaris | 256 | 2024-12-15 | 2024-12-20 | F |
| 5678 |
How I use :dbconnection in org files
In the post "Followup on secrets in my work notes" Magnus Therning mentions a feature in Org Babel I contributed to (in ob-sql.el, to be more precise).
You can see my old post for details about that feature, but basically,
the patch allows one to use a :dbconnection header argument in a
source block to reference a connection defined in
sql-connection-alist.
The question in Magnus' post is a signal somebody is actually using this feature, so I am pleased. Perhaps I should also follow up, describing how I use this feature in my workflow. This will constitute another example of how to manage secrets.
I use Org, among other things, to keep work "lab notes" that usually contain SQL queries on different databases.
At work, pretty much all databases are Postgresql or Redshift, and I
keep connection details in ~/.pgpass, following this format:
In other words, every DB definition is made of two lines: the first is a comment, with the name of the database (with no spaces); the second contains the actual connection details.
In my Emacs configuration, then, I have this function:
(defun get-connection-alist (filename)
"Gets PG connections details from ~/.pgpass file (FILENAME)."
(with-current-buffer (find-file-noselect filename)
(let ((lines (split-string (buffer-string) "\n" t)))
(when lines
(cl-loop for (k v) in (seq-partition lines 2)
collect (cl-destructuring-bind (host port db user password)
(split-string v ":" nil)
`(,(replace-regexp-in-string "^#\s+" "" k)
(sql-product 'postgres)
(sql-port ,(string-to-number port))
(sql-server ,host)
(sql-user ,user)
(sql-database ,db)
(sql-password ,password))))))))
and
(setq sql-connection-alist (get-connection-alist "~/.pgpass"))
I use Emacs in daemon mode and it's not unusual Emacs to stay up for
weeks, so I also have an automatic way to incorporate .pgpass changes,
using filenotify.
(file-notify-add-watch
"~/.pgpass" '(change)
(lambda (evt)
(setq sql-connection-alist
(get-connection-alist "~/.pgpass"))))
Reactions and follow ups
- Andreas Gerler describes his approach and setup here: Emacs and SQL
The Hygieia Fountain in Hamburg
I recently spent a weekend in Hamburg to visit friends. While exploring the city my attention was caught, for some reason, by the fountain situated in the courtyard of the city hall, and the sculptures that surround it. It's called Hygieia Fountain.


Hygieia as the goddess of health and hygiene in Greek mythology and its surrounding figures represents the power and pureness of the water. It was built in remembrance of the cholera epidemic in 1892, the former technical purpose was air cooling in the city hall
1337
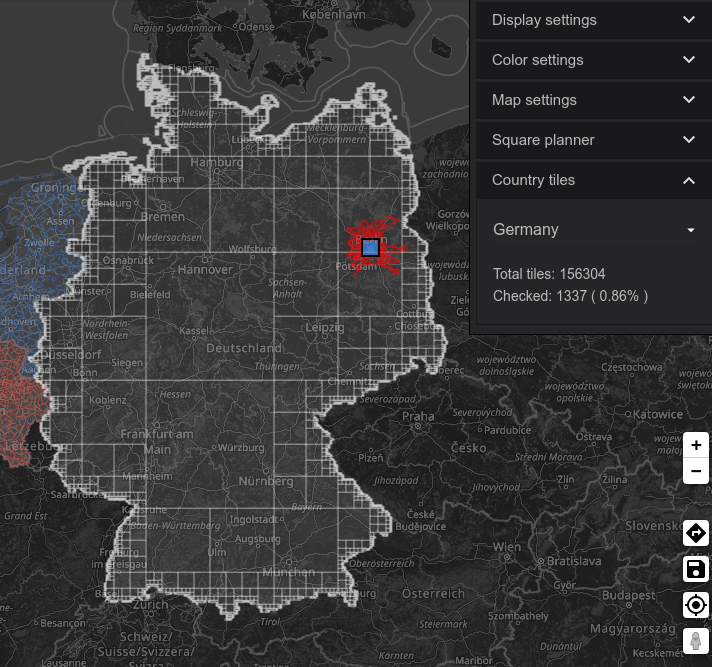
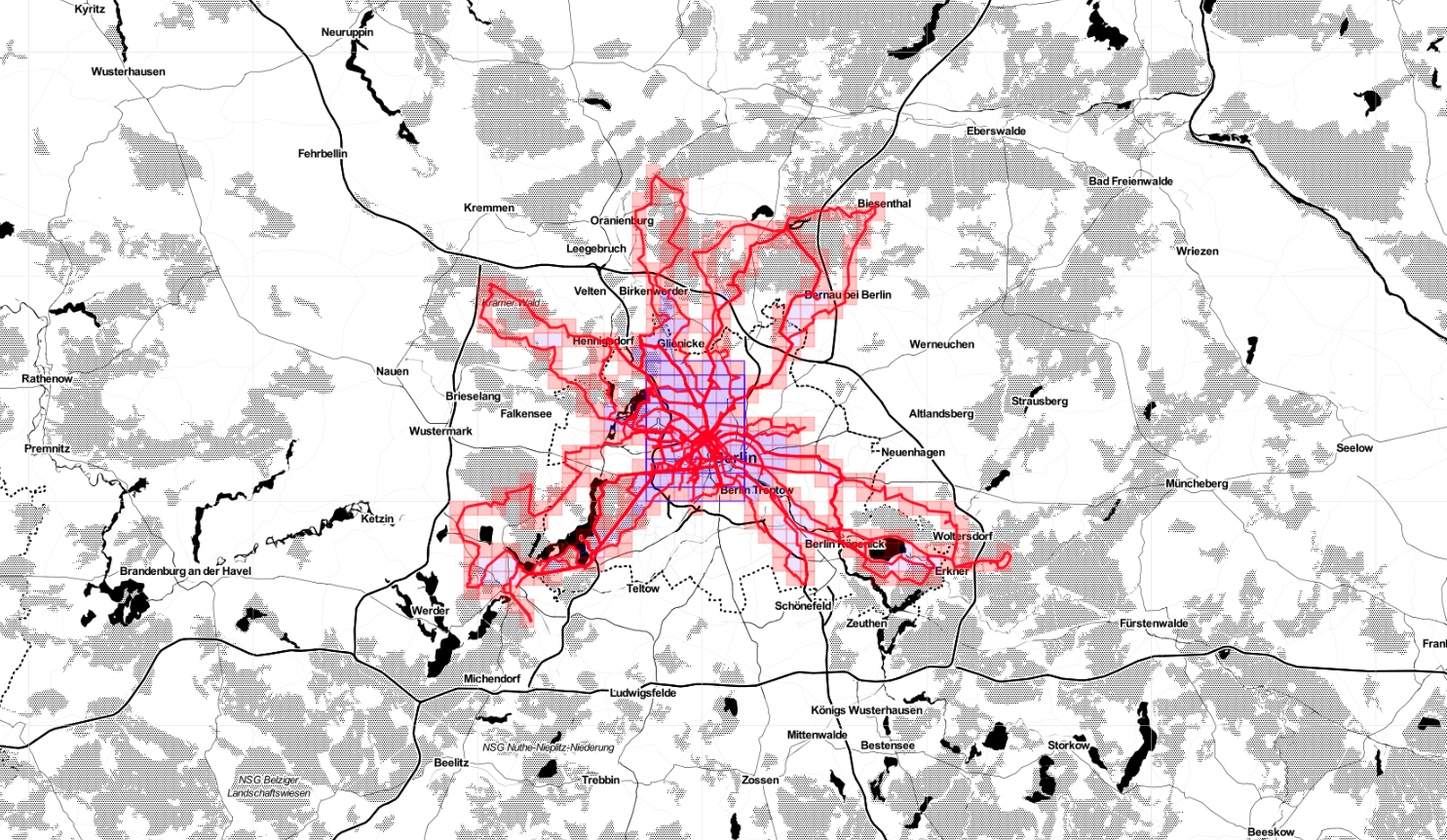
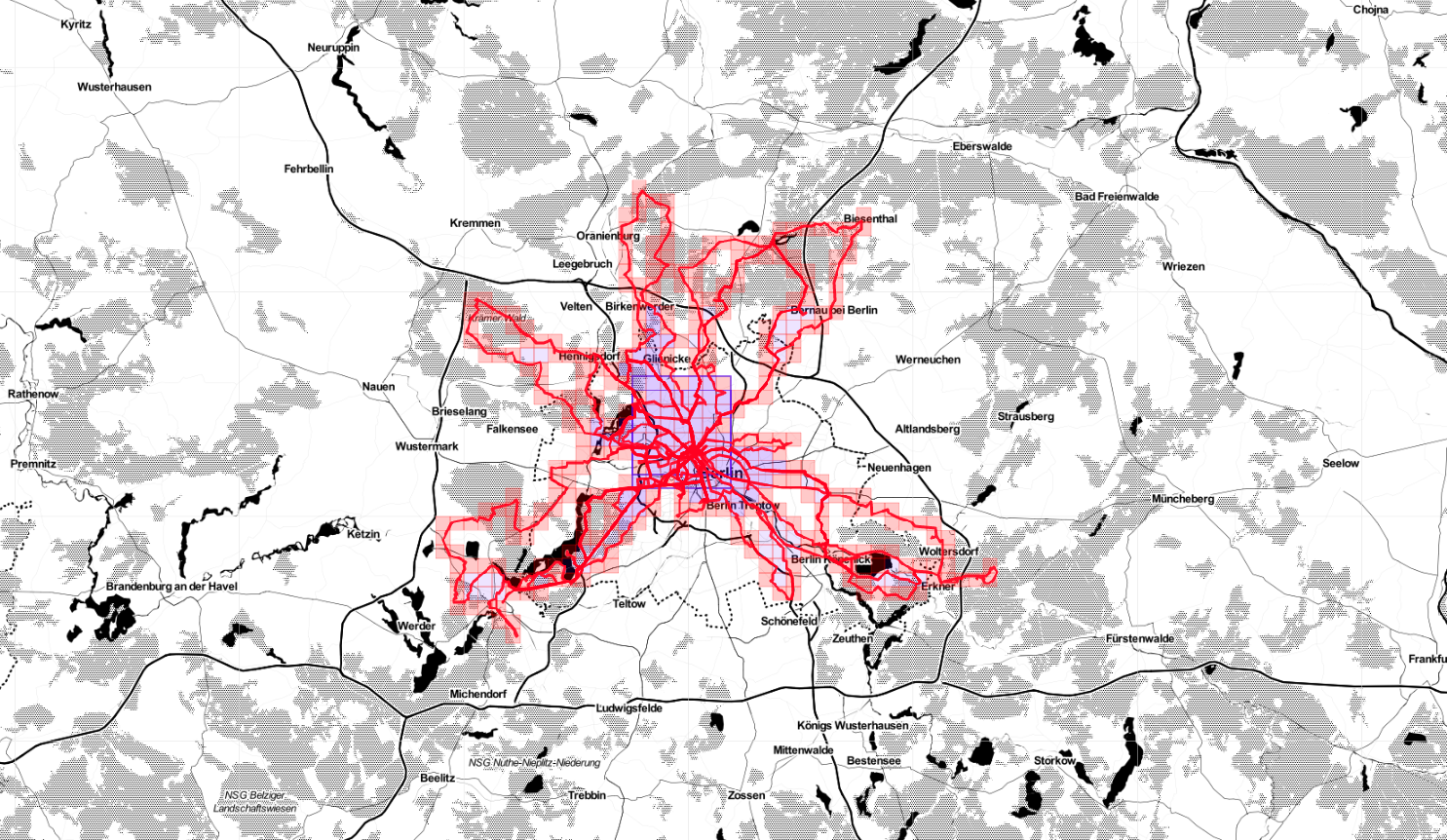
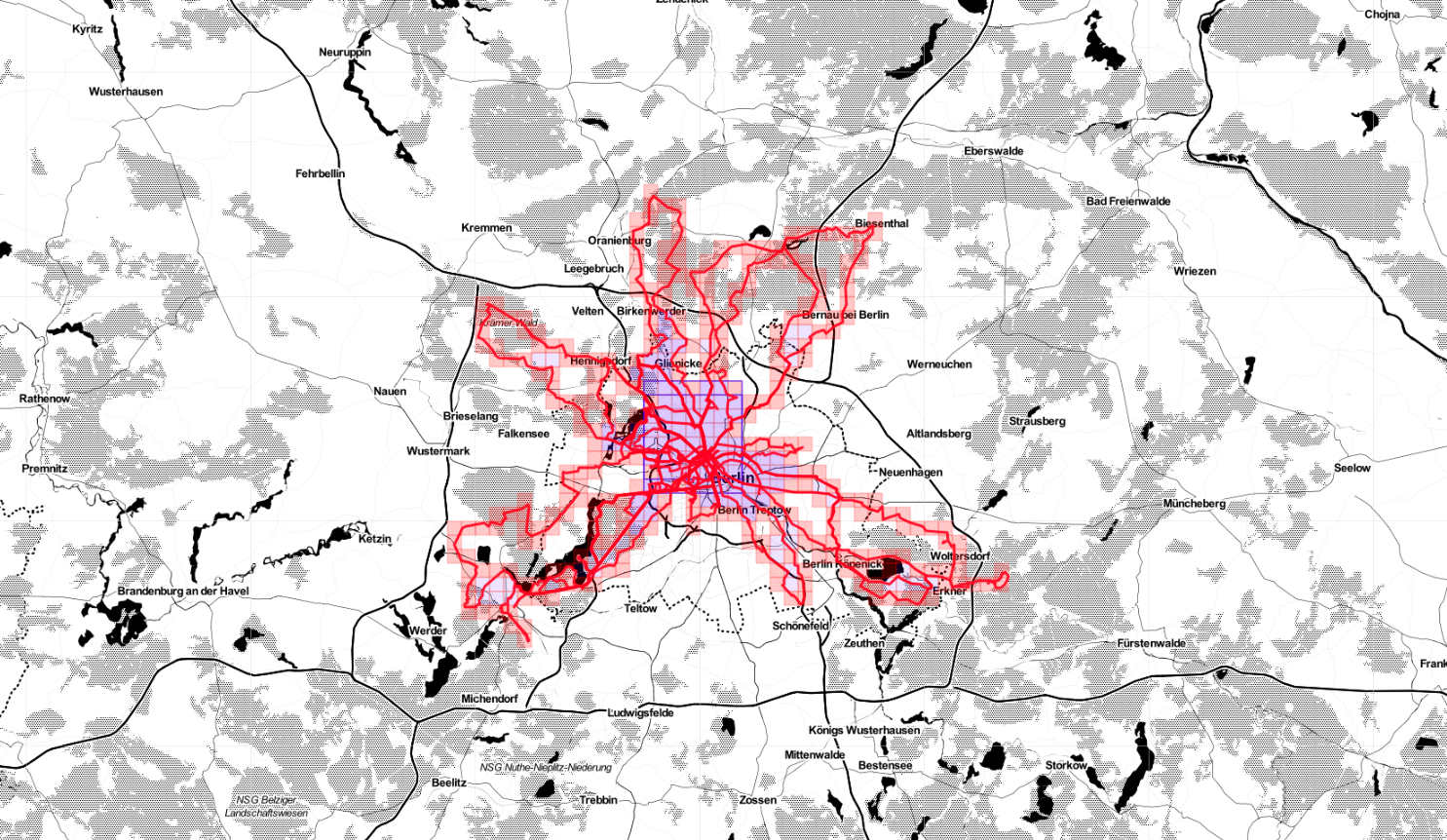
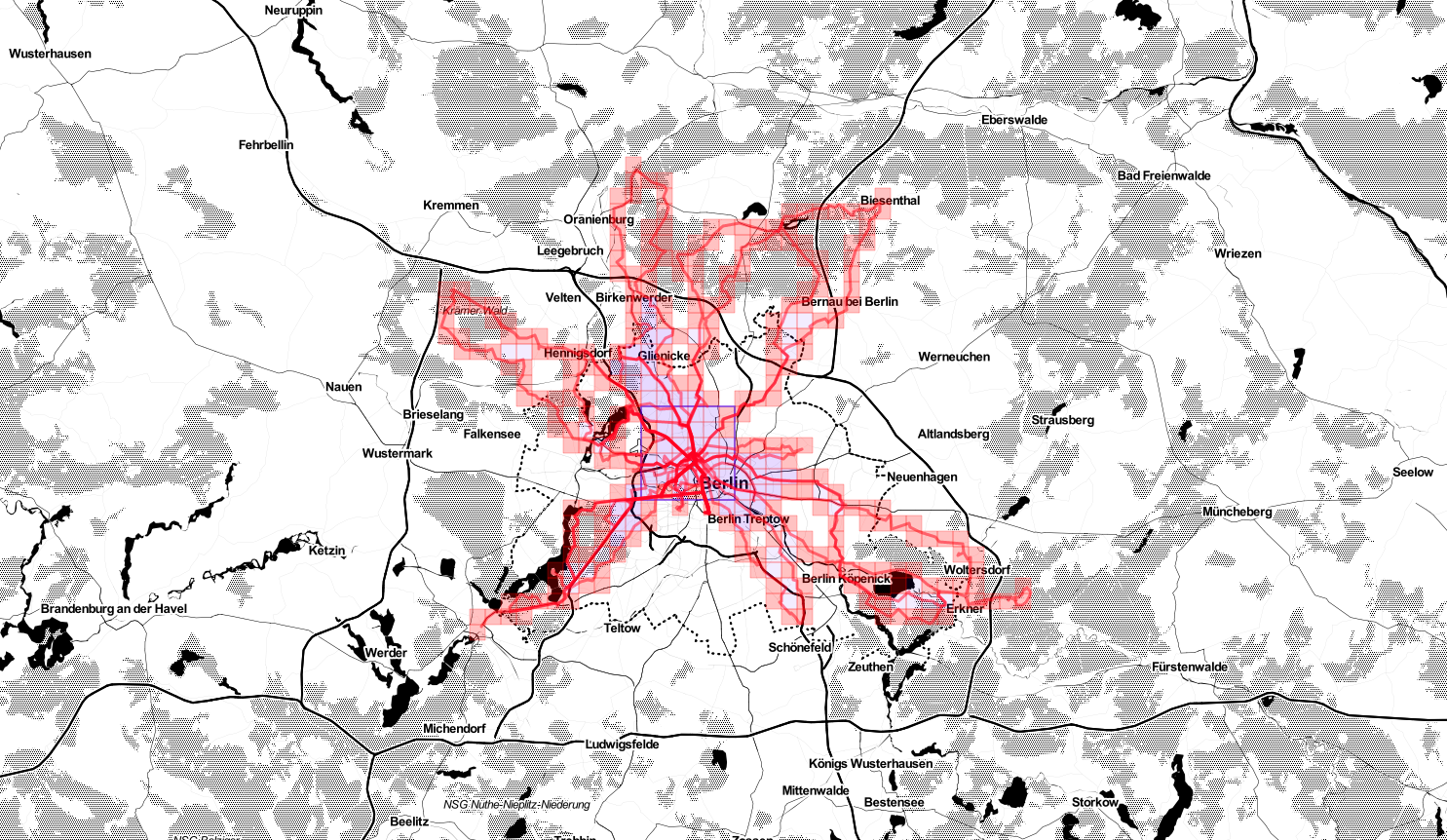
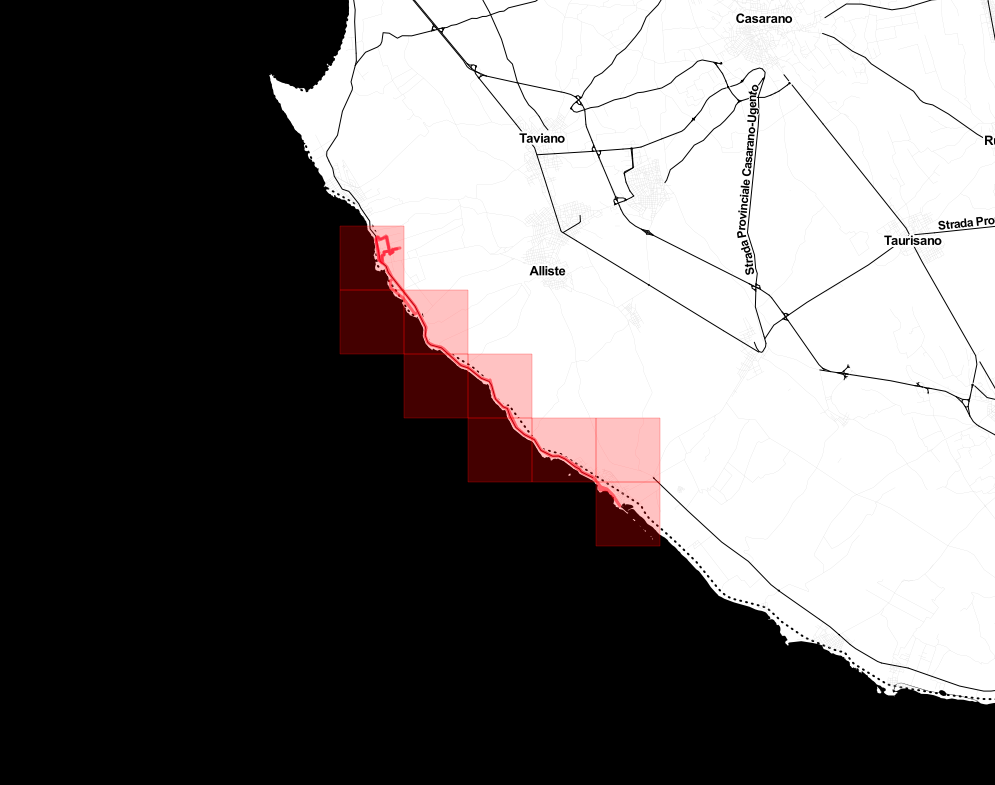
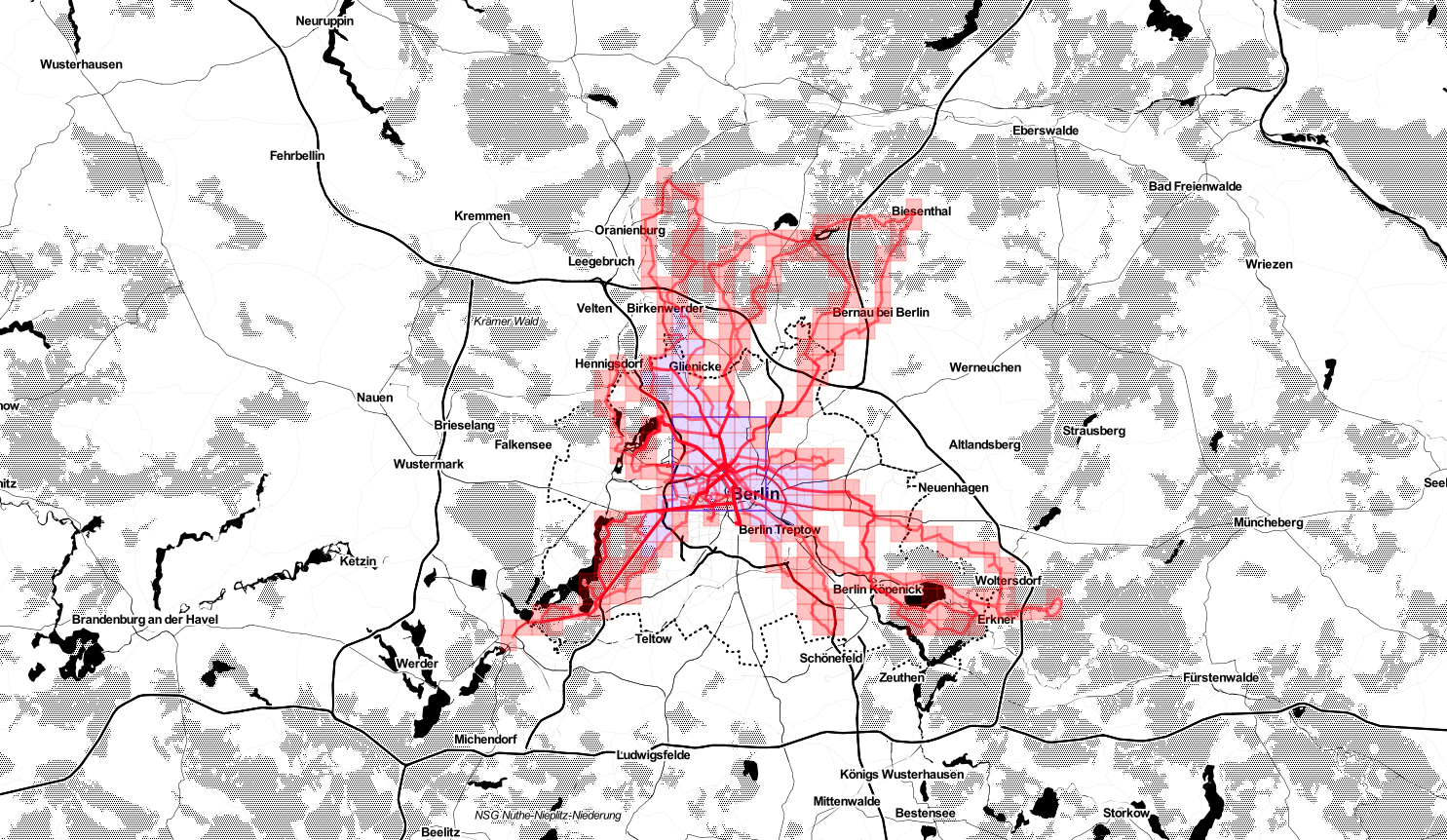
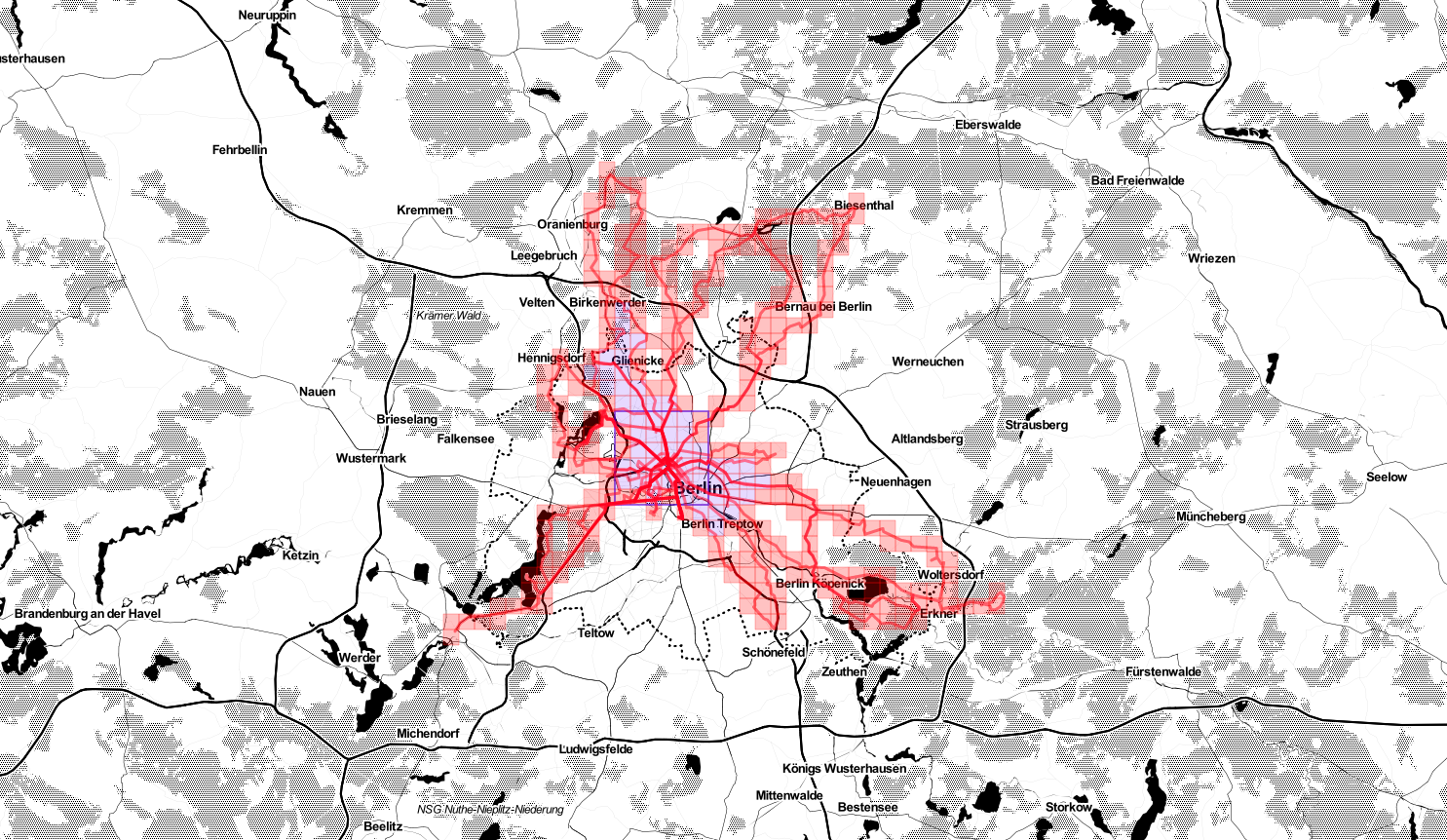
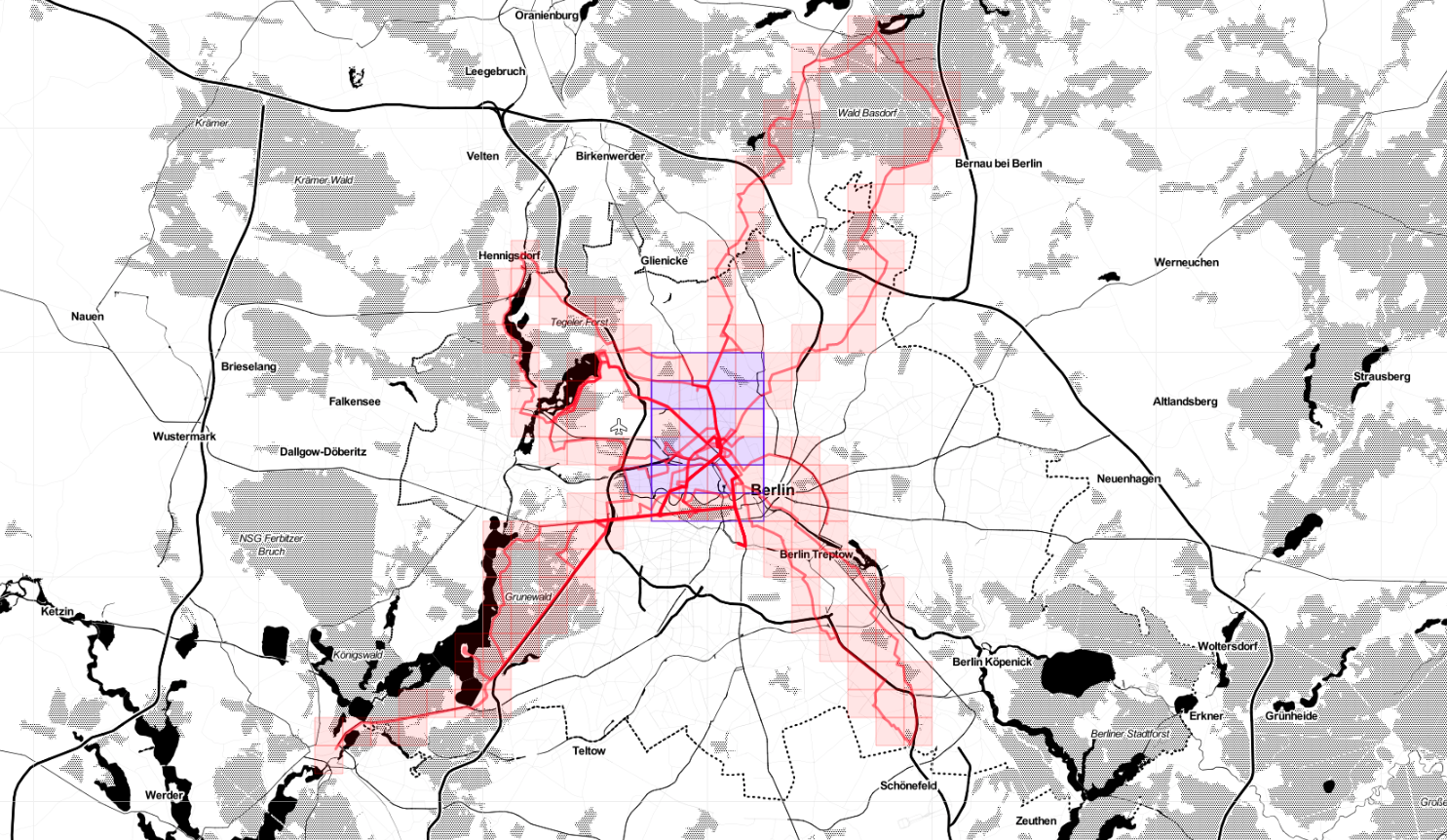
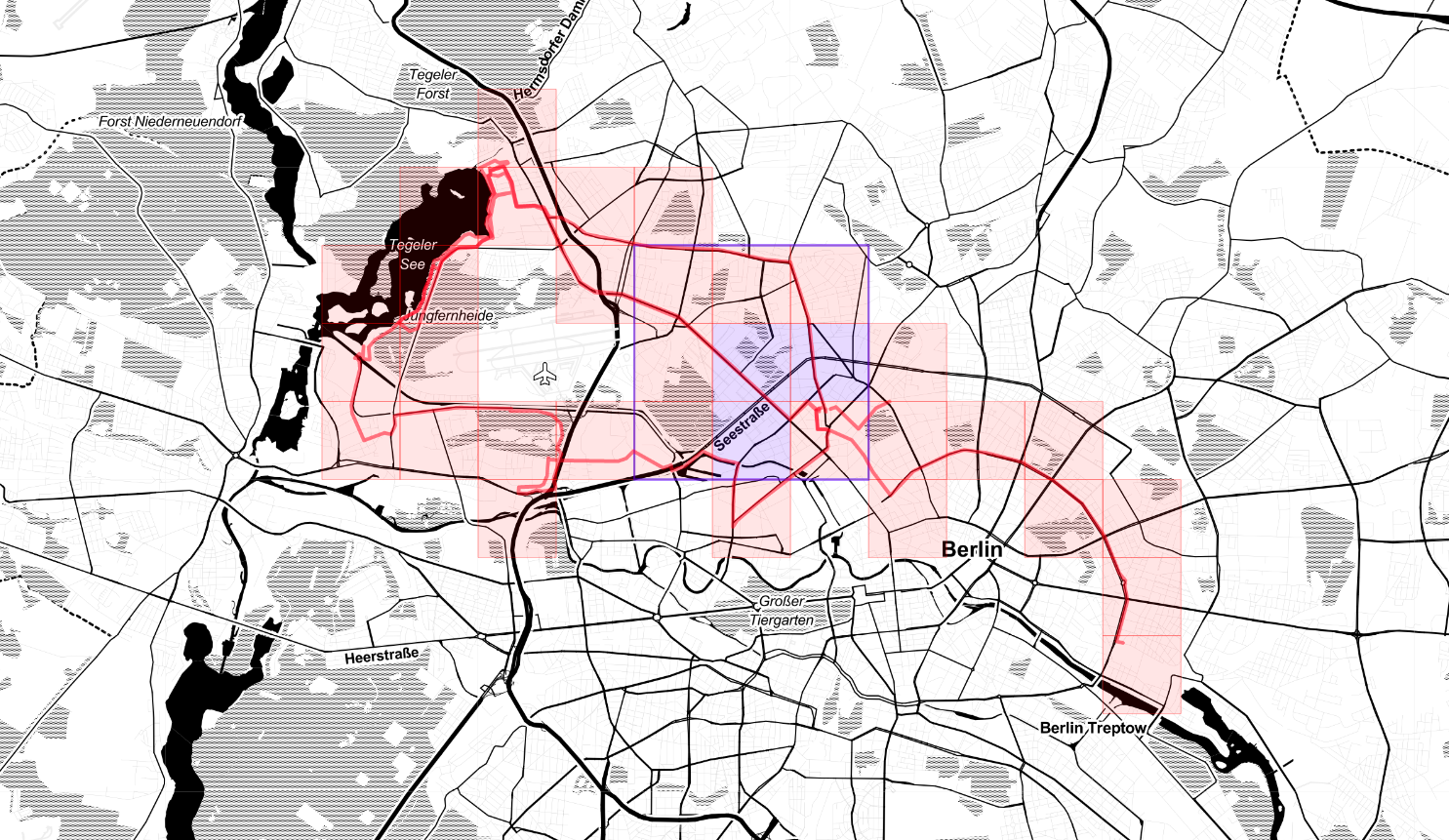
According to Statshunters so far I covered a non-random number of squares in Germany.
A weekend in London

After many years since my last visit, I spent a long weekend in London. Among my various impressions, I note that I didn't touch any cash whatsoever for the entire stay. Even more: if it weren't for a guy in front of me at the cash register in a pub, who was paying with a banknote, I would've not seen any cash during my visit. I imagine this can lead to overspending, but nice.
Exporting content from org-roam to arbitrary org files
I adopted org-roam to collect and manage my personal notes. I also use Org for managing the pages of my personal website (this site). My notes are mostly personal, as I said, but sometimes I want to publish them on the website.
So far the process has been manual: when I had significant updates to publish I just copied text from one org file (in org-roam) to another. But I wanted something more systematic.
I therefore added this two functions in my Emacs configuration
(defun my/remove-org-roam-links (buffer-as-string)
(replace-regexp-in-string
"\\[\\[id:.*\\]\\[\\(.*\\)\\]\\]" "\\1" buffer-as-string))
(defun my/paste-org-roam-node (initial-input &key no-links)
(interactive)
(let* ((file (org-roam-node-file (org-roam-node-read initial-input)))
(raw-buffer (with-current-buffer (find-file-noselect file)
(goto-char (point-min))
(buffer-string))))
(if no-links (my/remove-org-roam-links raw-buffer)
raw-buffer)))
Then I can use a snippet like this in the destination buffer
#+begin_src emacs-lisp :results value raw append (my/paste-org-roam-node "through" :no-links t) #+end_src
And this appends to the file the contents of the original org-roam note (I happen to have a note titled "Through the Language Glass", so that 'through' is enough to identify a node), after stripping, if requested, the links to other notes.
There's still some manual work to do before one can post, but this solution is already an useful improvement.
TODO
[ ]the operation is not idempotent[ ]org-roam-node-readstill requires the user to hit return in the minibuffer to confirm the choice. I'd rather have no interaction after invoking the command byC-C C-C[ ]after the note content is appended to the file, there's some clean up to do: removing unwanted metadata from the original buffer, and so on…[ ]it seems there are problems with the management of footnotes, if present in the original note
Custom CSS for my website
My website is intentionally unadorned, but not because I don't like colors or typography. It's just I want the site to load as fast as possible, and I don't want to impose JS automatisms or othe shenanigans like these.
Actually, when I browse my pages myself, I use browser add-ons to apply a personalized CSS and even some JS facility. And I change the style often. Here how it currently looks like.

And the respective CSS and JS I use with User JS and CSS Chrome extension to implement it.
https://stefanorodighiero.net/misc/personal.css
https://stefanorodighiero.net/misc/personal.js
Switching from stream to blog
I wanted to transform my stream for a long time, switching from a single .org file where I kept adding things, to a more appropriate blog structure, with individual posts, index, archive, tag pages, a feed and so on. Thanks to Org, it was relatively easy to use the original material to produce the files I then fed to org-static-blog.
Here the code I used (I just omitted a few service functions)
(defun split-org-file (input-file output-dir)
"Split an .org file into separate files for each top-level entry.
INPUT-FILE is the path to the .org file.
OUTPUT-DIR is the directory where the separate files will be saved."
(with-current-buffer (find-file-noselect input-file)
(goto-char (point-min))
(org-map-entries
(lambda ()
(let* ((entry-title (nth 4 (org-heading-components)))
(tags (parse-tags-into-filetags
(nth 5 (org-heading-components))))
(ts (get-timestamp-from-title entry-title))
(entry-title-stripped (strip-entry-title entry-title))
(output-file (expand-file-name
(format "%s.org" (dirify-string entry-title-stripped))
output-dir)))
(let ((body (org-copy-subtree))
(cleaned-body (with-temp-buffer
(insert (car kill-ring))
(goto-char (point-min))
(when (re-search-forward "^\\*+ \\(.*\\)$" nil t)
(replace-match "" nil nil))
(buffer-string))))
(with-temp-file output-file
(insert (format "#+title: %s\n" entry-title-stripped)
(format "#+date: %s\n" (or ts "2000-01-01"))
(format "#+filetags: %s\n" (or tags ""))
"\n\n"
(format "%s" cleaned-body))))))
"LEVEL=1")))
Venetogravel finisher stats
The organization of Venetogravel published the finisher stats for the 2024 edition. I grabbed this data and the datapoints from 2023 to plot some charts.
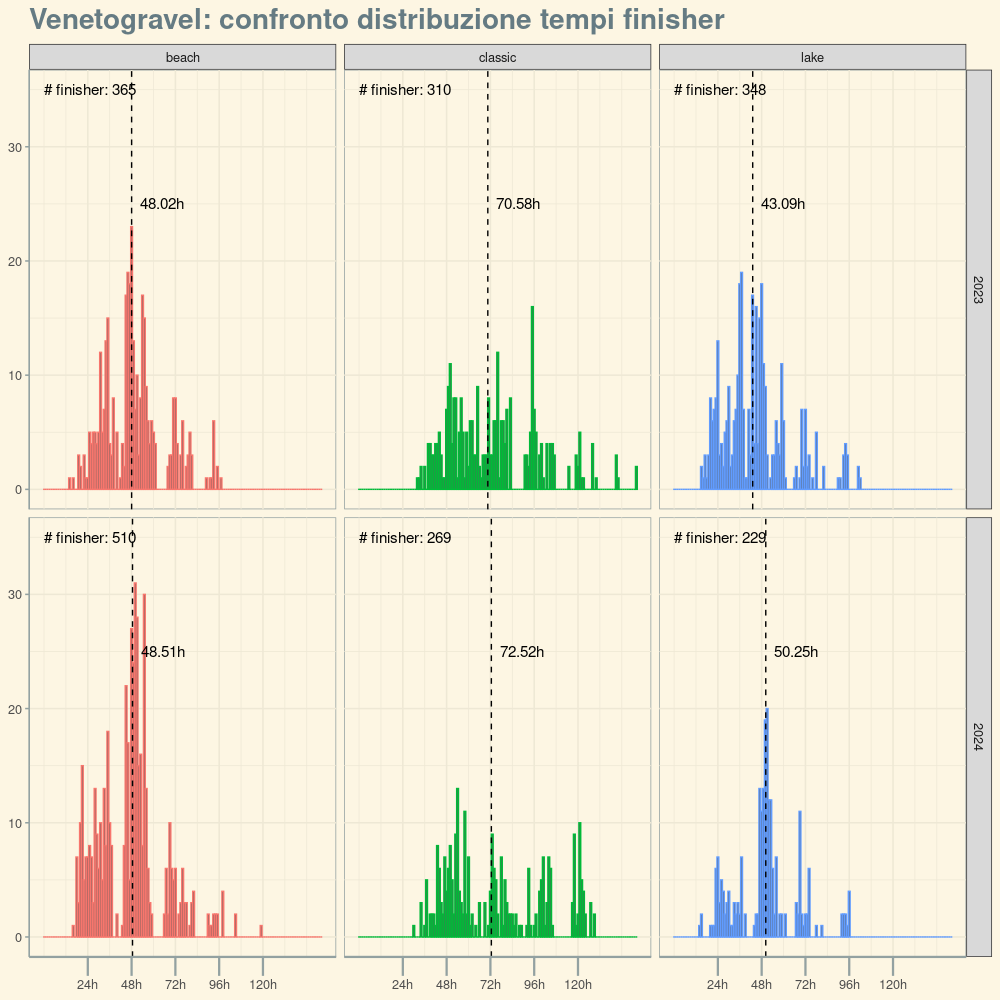
"beach", "classic" and "lake" represent three different routes each participant could choose from, respectively ~400km (2800m total ascent), ~720km (4300m), ~400km (1800m). The editions of 2024 and 2023 presented the same choices, with the major difference that the direction of the routes was reversed. 2024's edition had also a new 200km (2800m) option which I didn't analyze.
I was interested to see if the median finisher time (indicated by the dashed line in the charts) would change, which I intended as a possible answer to the question "Would reversing the direction make the routes easier or harder?".
Data show that for "classic" and "beach" it didn't change, but the value is significantly higher for 2024 for the Lake route. (I, by the way, completed the Lake route in 53 hours and 16 minutes).
Not sure how to explain that. It's true the weather was worst in 2024, and I know several cyclists (including me) were blocked by a storm on Sunday, but that lasted only a couple of hours, not enough to explain the significant increase in median time.
Perhaps the population of cyclists that chose the Lake route was made of less experienced athletes, that had to take more time to complete it. Not sure.
How I made the charts
First I load and transform the files I obtained from the website:
classic2023 <- processfile("2023/data/classic.txt", "classic", 2023)
beach2023 <- processfile("2023/data/beach.txt", "beach", 2023)
lake2023 <- processfile("2023/data/lake.txt", "lake", 2023)
classic2024 <- processfile("2024/data/classic.txt", "classic", 2024)
beach2024 <- processfile("2024/data/beach.txt", "beach", 2024)
lake2024 <- processfile("2024/data/lake.txt", "lake", 2024)
here the body of processfile:
convert_elapsed_time_to_minutes <- function(elapsed_time_str) {
time_parts <- str_split(elapsed_time_str, ":")[[1]]
hours <- as.integer(time_parts[1])
minutes <- as.integer(time_parts[2])
total_minutes <- (hours * 60) + minutes
result <- total_minutes
}
processfile = function(filepath, track, year) {
df <- read.table(
text=gsub(" – ", "\t", readLines(filepath)),
sep="\t"
)
names(df) <- c("country", "name", "elapsed_time")
return(df
%>% rowwise()
%>% mutate(elapsed_time_minutes = convert_elapsed_time_to_minutes(elapsed_time))
%>% mutate(track = track)
%>% mutate(year = year)
%>% filter(elapsed_time_minutes > 0)
%>% filter(elapsed_time_minutes < 10000) # filter outliers
%>% select(country, track, year, elapsed_time_minutes)
)
}
Then we put together these dataframes, and compute some aggregated stats
data <- bind_rows(classic2023, beach2023, lake2023,
classic2024, beach2024, lake2024)
data_medians <- data %>% group_by(year, track) %>% summarize(x=median(elapsed_time_minutes))
data_count <- data %>% group_by(year, track) %>% summarize(x=n())
We're ready to produce the chart using ggplot:
x_labels <- function(m) {
res <- round(m / 60, 2)
paste(res, 'h',sep = "")
}
ggplot(data, aes(x=elapsed_time_minutes, color=track)) +
geom_histogram(binwidth = 60) +
facet_grid(cols=vars(track), rows = vars(year)) +
geom_vline(data = data_medians, aes(xintercept = x),
linetype="dashed") +
geom_text(
data=data_medians,
aes(x=x, label=x_labels(x), y=25),
size = 4,
nudge_x=+1000,
color = 'black'
) +
geom_text(
data=data_count,
aes(x=0, label=paste("# finisher:", x), y=35),
size = 4,
nudge_x=1500,
color = 'black'
) +
scale_x_continuous(breaks=c(60*24, 60*48, 60*72, 60*48*2, 60*24*5),
label=x_labels) +
xlab("Tempo totale") +
ylab("Numero di finisher") +
theme_solarized() +
theme(
legend.position = "none",
axis.title = element_blank(),
axis.line.x = element_line(linewidth=.8),
axis.ticks.x = element_line(linewidth = .8) ,
axis.ticks.length.x = unit(.5, "cm"),
panel.border = element_blank(),
panel.grid = element_blank(),
plot.title = element_text(face="bold", size=21)
) +
ggtitle("Venetogravel: confronto distribuzione tempi finisher")
Using Clerk to plan bikepacking events
I have been experimenting with Clerk to build a tool I can use to study different strategies for Venetogravel 2024. Inputing parameters such as the distance I have to cover, the average speed I think I can maintain during the event, and how I intend to distribute the effort over several days, I can obtain a diagram. It's a work in progress, here what I got so far:
(def plan-start-19
{:description "Starting on April 19th"
:daily-plans [{:label "Day 1"
:activities [{:start "15:00" :length 6 :type :ride}]}
{:label "Day 2"
:activities [{:start "07:00" :length 5 :type :ride}
{:start "17:00" :length 3 :type :ride}]}
{:label "Day 3"
:activities [{:start "08:00" :length 6 :type :ride}]}]})
which results in
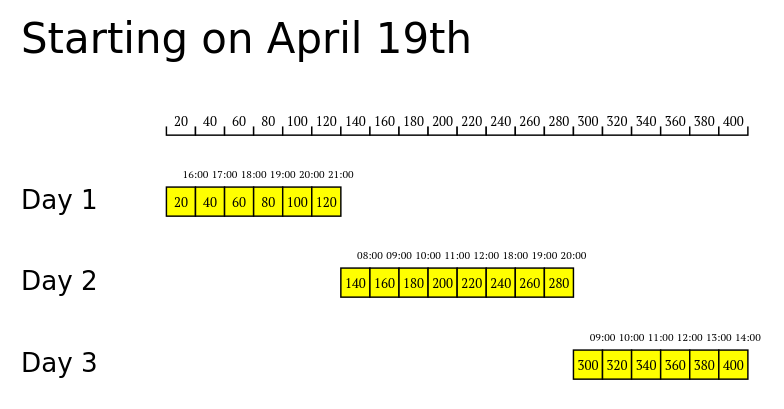
To do:
- integrate data from GPX files (altitude is fundamental)
- learn how to rotate entities with SVG (transformations seem to work in the least intuitive ways)
Bikepacking updates
I only managed two overnighters during this season, but I learned something on how to pack, reaching a nice setup for my kit.

The setup is now more compact and feels more comfortable.
The front bag contains the sleeping bag (15 ⁰C) and both the tent layers (Naturhike Cloudup 2). I didn't think it was possible, but it was just a matter of squeezing (and believing) harder. Also, not using compression bags helps, because this way the material is more free to occupy all available space.
This makes the front bag slightly wider, so I had to add spacers to keep it clear of the levers.
I added an Ortlieb accessory bag on the front, where I put food and some kitchen tools (nothing particular, a collapsible bowl, sporks, … stuff like that)
The saddle bag is much smaller and shorter, which makes the bike easier to handle. It now contains just the mat, the tent base layer, stove + pot (another new addition to my kit), and clothes.
I am quite satisfied with the results. One thing I have to learn is how to re-pack things so that dirty or slightly soggy clothes don't ruin other clean items; this would allow me to do longer journeys.
Org-roam
I started experimenting with org-roam (v2, with org-roam-ui to have an idea of the progress). Still not entirely clear to me, but I will continue.

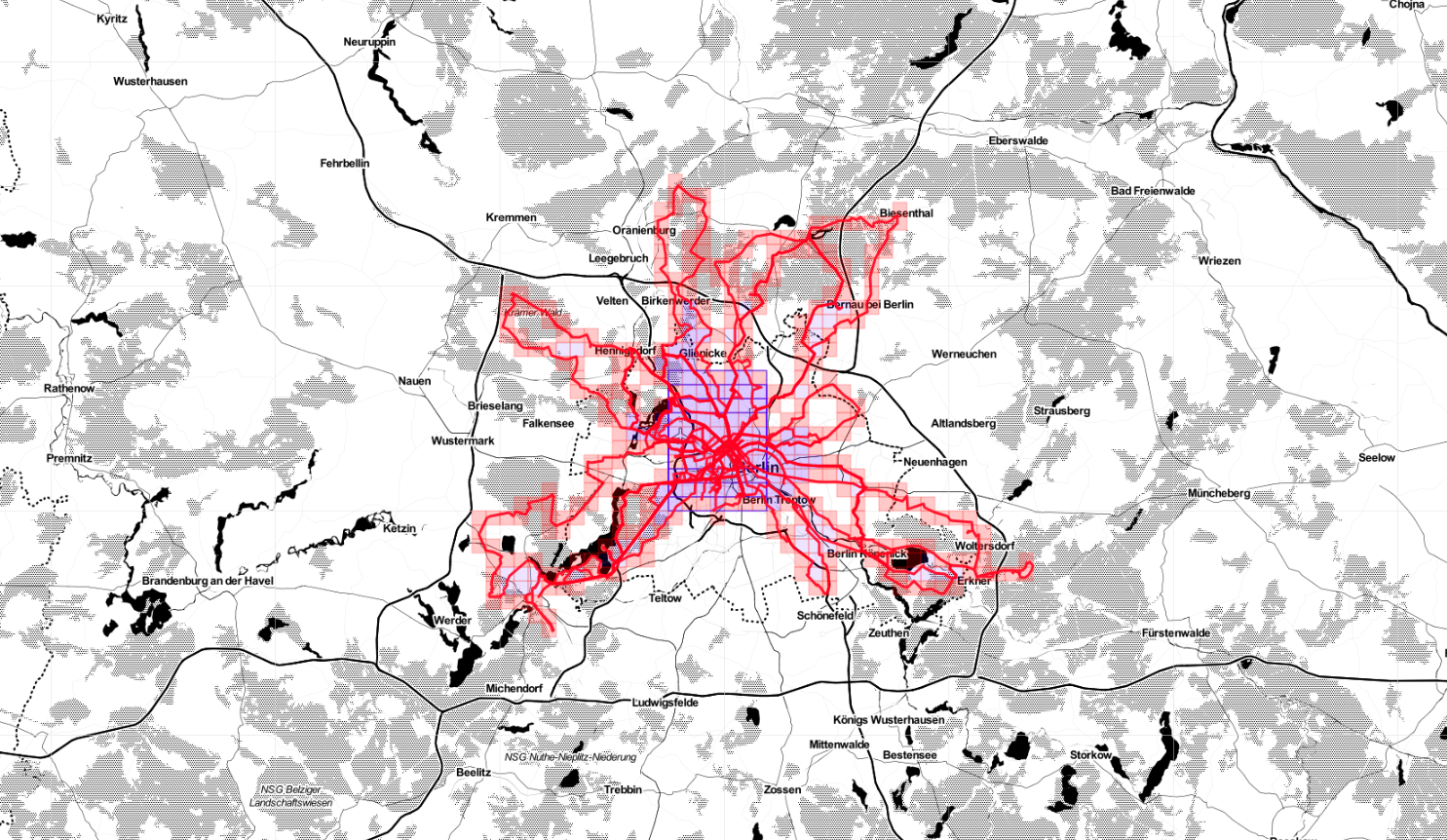
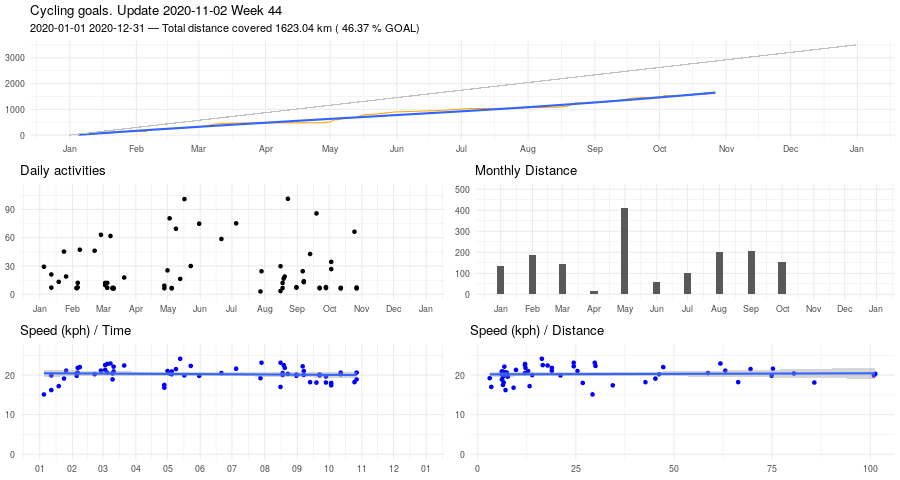
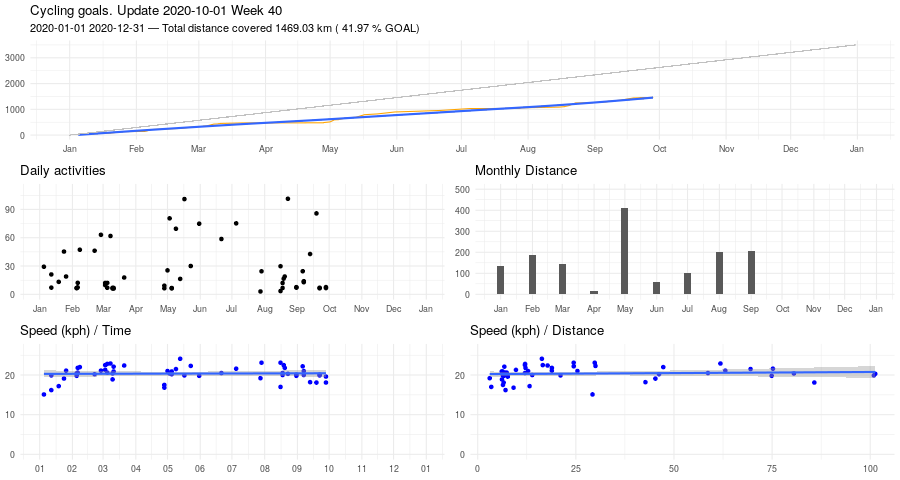

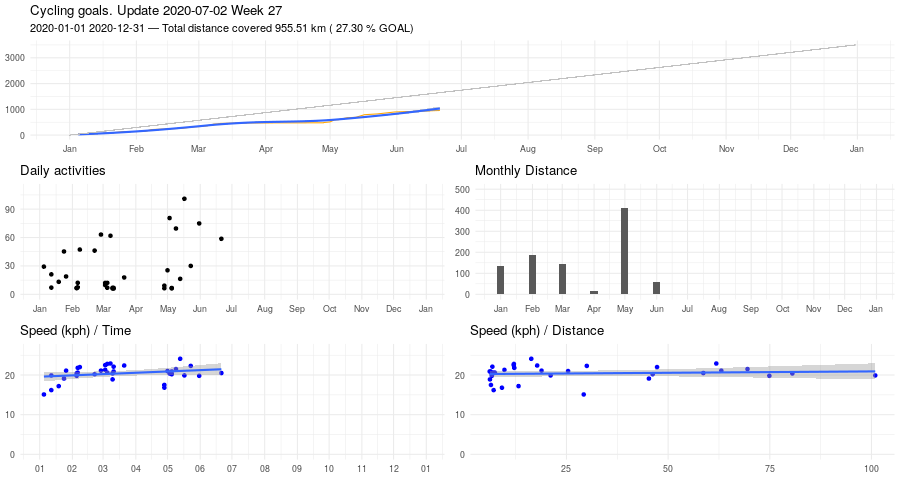
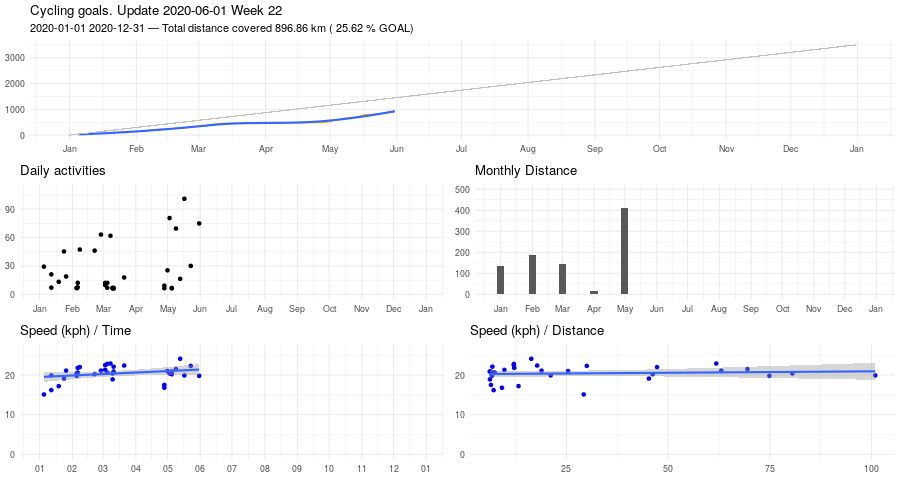

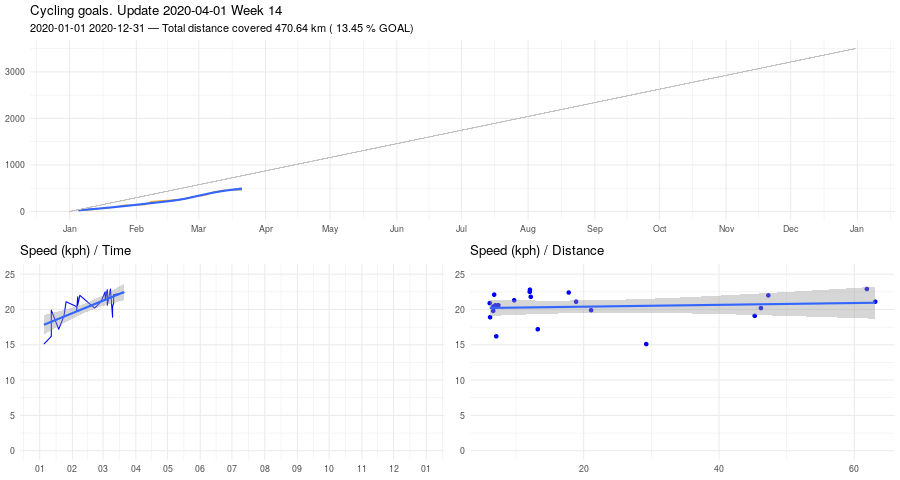
Biking, March update
Started well. Abrupt stop: riding in the midst of COVID19 related restrictions didn't feel right.
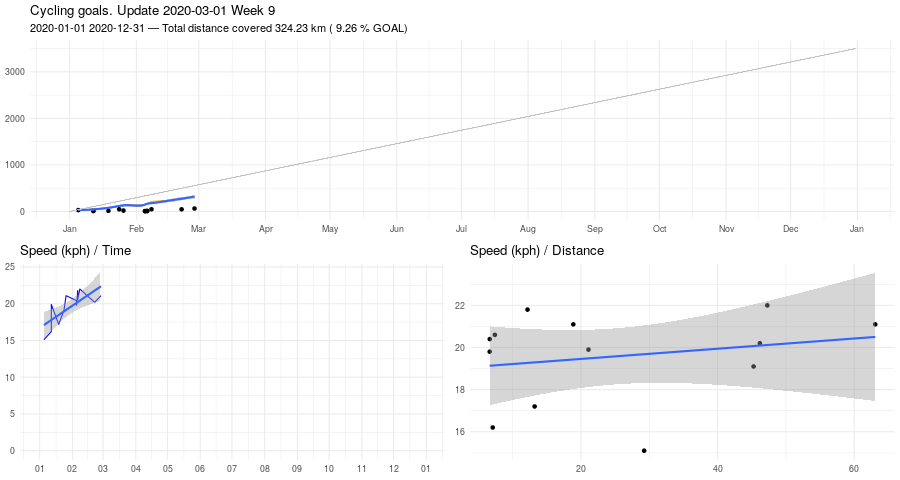
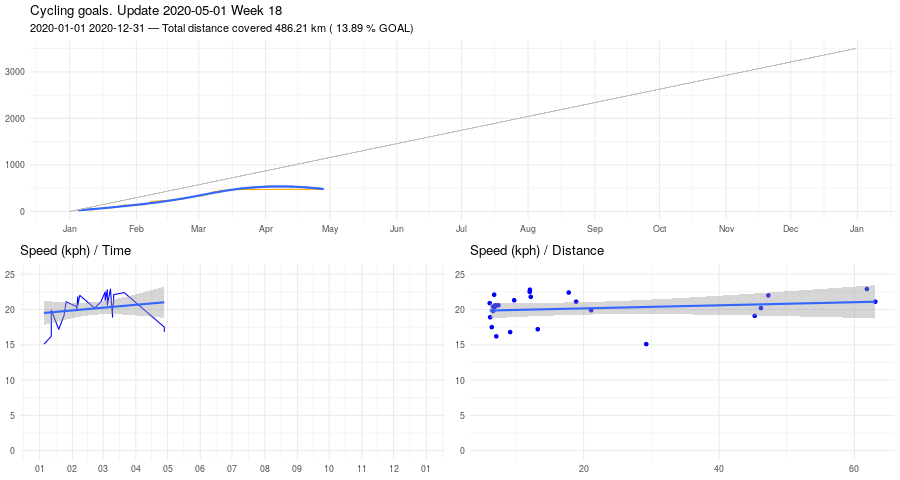
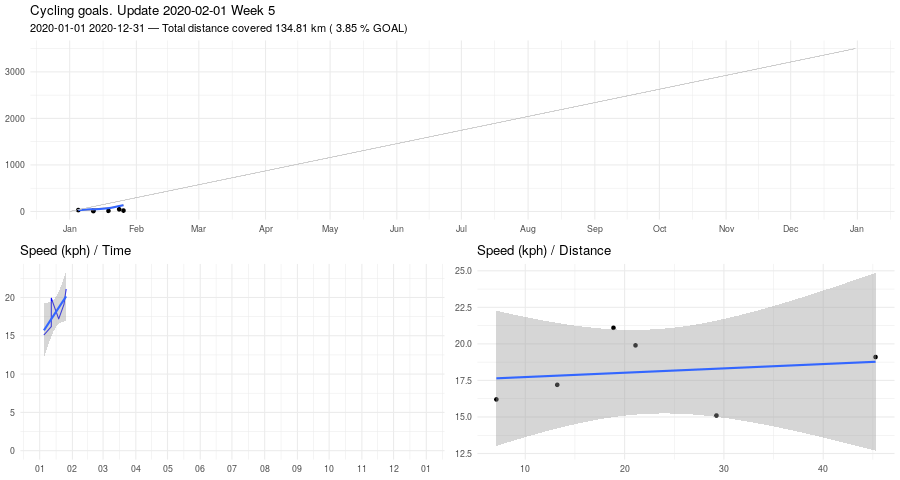
Biking, January update
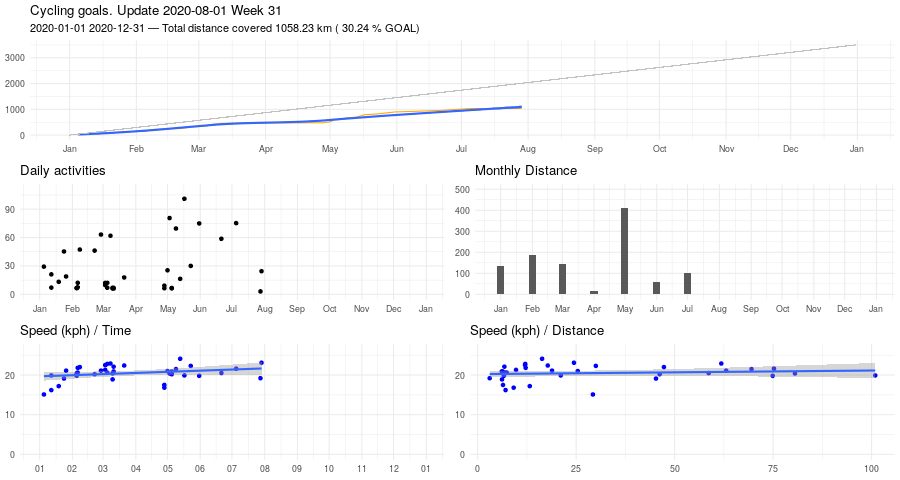
Here some stats about January.
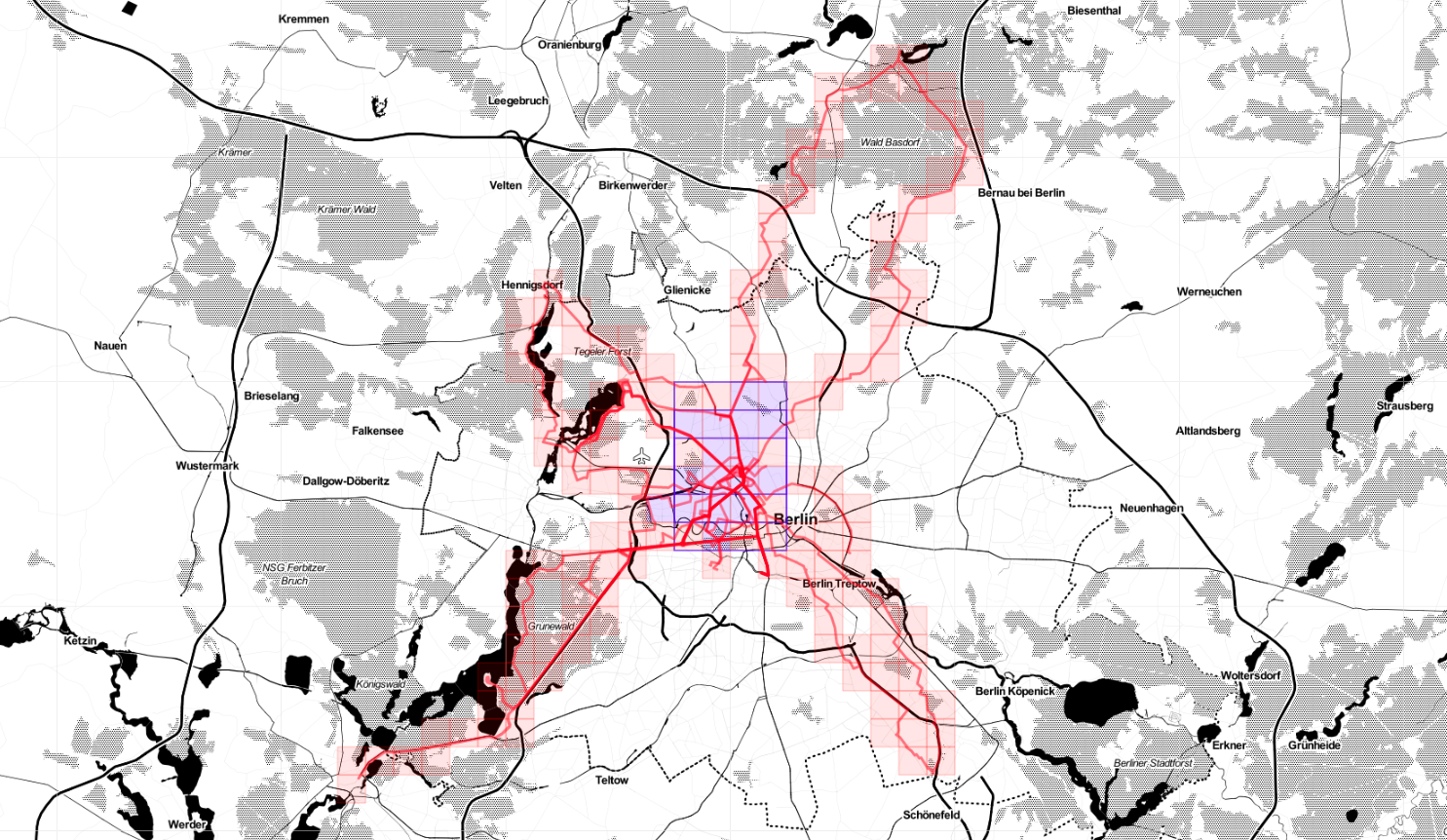
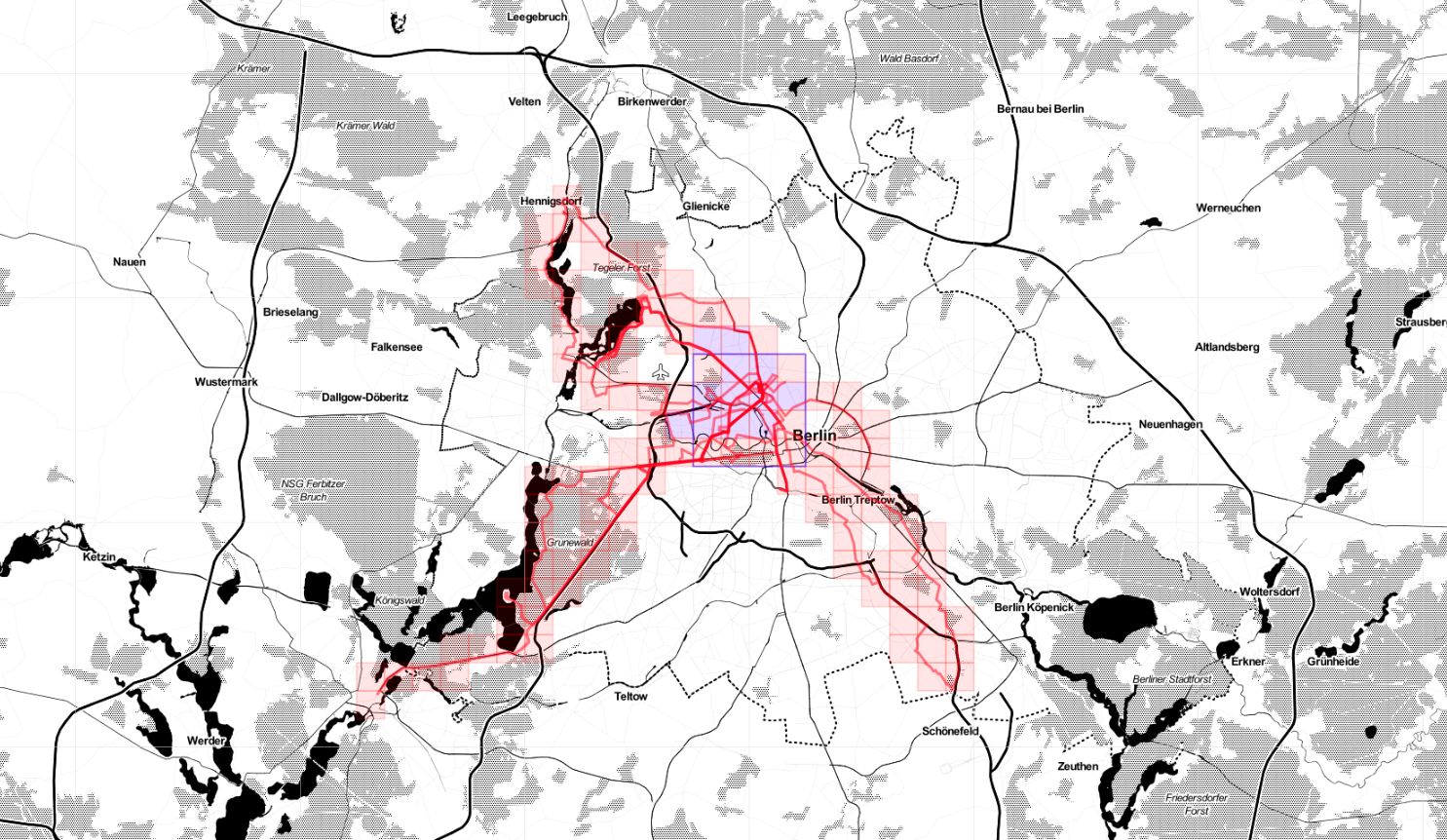
And here Veloviewer's map update. Max square still 3x3, but I covered more territory.
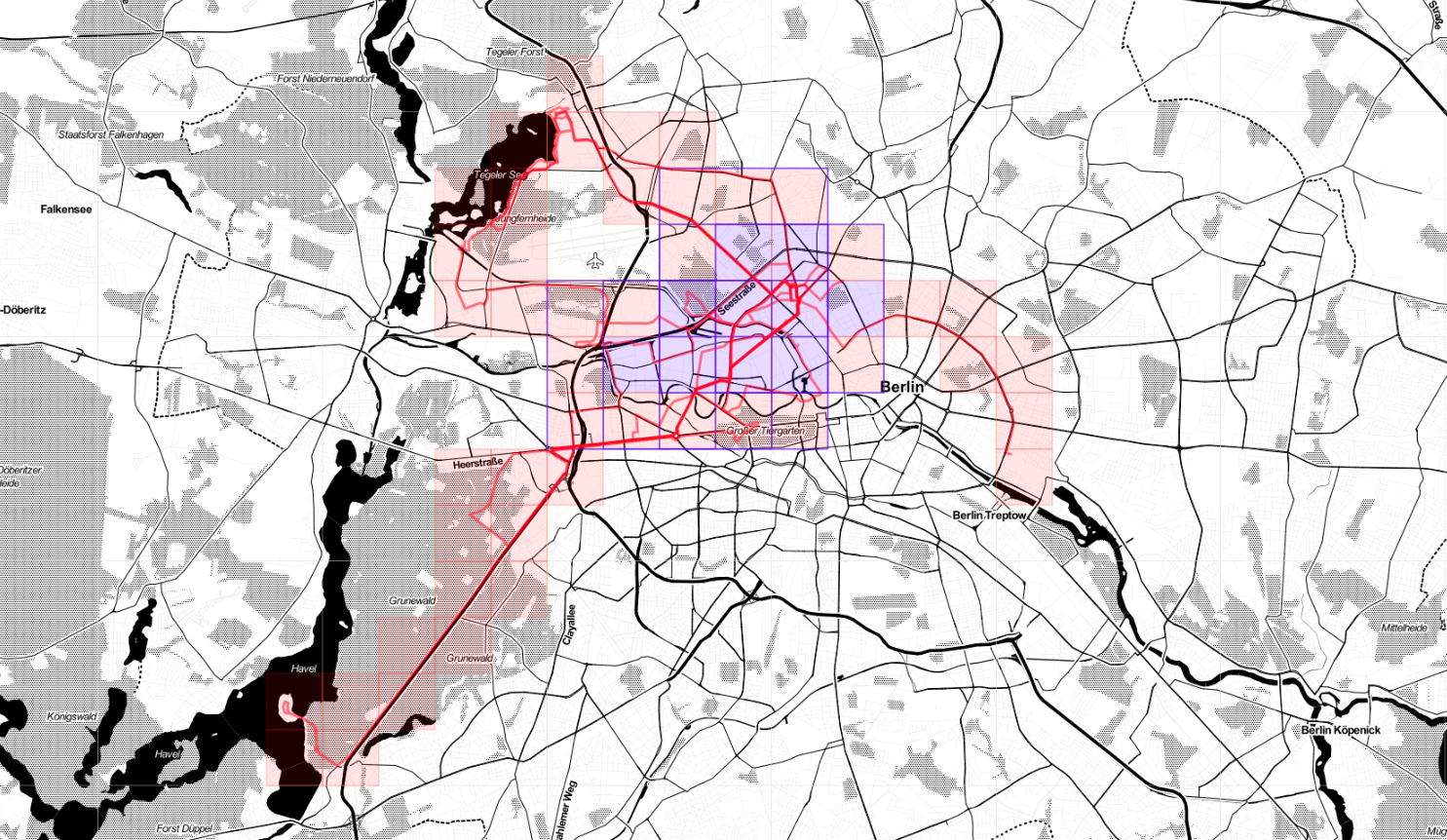
Veloviewer stats
One of the fun parts of riding a bike is generating stats. Using Veloviewer (via Strava), for example, one can compute the max cluster size of his activities. Mine is 3x3, at the moment.
Plans for 2020
I don't particularly like the plans-for-next-year literary genre, but I imagine it will be fun to read this at this very same time next year: a memento of what my focus was. Anyway, here what I'd like to start, stop and continue doing next year.
- Reading more books than those I read during 2019.
- Contribute to an open source project. In 2019 I was particularly happy because I managed to get a patch accepted for a tool I use daily (org-mode).
- Riding my bike for a total of 3500 km. I only recently got more
serious about biking. At the moment I am not interested at all in
speed and pure performance: for me it's more about exploring and
spending time outdoor, but yet I started collecting data.
- Why 3500? I initially thought 3000, because it's a nice round number. But it didn't make me unconfortable, as an objective should do. Adding 500 km does, yet it should not be a crazy stretch, especially if I develop the habit of using the bike instead of U-Bahn for commuting. I plan to post monthly reports here.
- As a sub-goal, I'd like to try bikepacking, at least for a weekend.
- Start and publish a software project: I had several ideas over the last years, but all of them didn't go beyond the explorative or half-baked idea stage.
- Make some efforts at learning German (I'd like to reach a level where I can read articles and simple books).
- Stop wasting my time.
- Continue tracking expenses, sleeping and physical activities.
Books I finished in 2019
Novels
Other books
- Through the Language Glass: Why the World Looks Different in Other Languages
- Radical Focus: Achieving Your Most Important Goals with Objectives and Key Results
- Seven Brief Lessons on Physics
- The Manager's Path: A Guide for Tech Leaders Navigating Growth and Change
- The Computer Boys Take Over: Computers, Programmers, and the Politics of Technical Expertise
- UNIX: A History and a Memoir

Changing style of Emacs' tooltips
It seems obvious now that I figured it out.
Some parts of Emacs GUI are not configurable through faces (obvious). My Emacs is compiled with GTK 3.0, so it uses that library to render some of the elements of the GUI (even more obvious). Tooltips are among those elements. So, in order to change their style, I need to intervene on the configuration of GTK. For example, I had this:
Creating a file ~/.config/gtk-3.0/gtk.css:
@define-color tooltip_bg_color #fff8dc;
@define-color tooltip_fg_color Black;
and restarting Emacs, I obtain this:
A patch for Org Babel
Org-babel allows SQL snippets to be run on a database connection that
can be specified in the source block header using parameters such as
:dbhost, :dbuser, :dbpassword and so forth.
This is very useful, but I'd also like to be able to use symbolic references to connections defined elsewhere, so that for example one does not have to specify the password every time, interactively or, worse, in the .org file itself.
I am also a user of sql.el, that provides a custom variable
sql-connection-alist, where users can define a mapping between
connection names and connection details.
The patch I submitted extends the behavior of org-babel-execute:sql so
that it's possible to specify a new param :dbconnection containing a
connection name, used for looking up sql-connection-alist.
Bürgerpark Pankow
is conveniently close to home (the picture was not taken in the park but just outside it, on my way back)

Books batch

- Nate Silver's The Signal and the Noise
- The Language Instinct by Steven Pinker
- The Wandering Earth by Cixin Liu. I heard about Cixin Liu for the first time when he was nominated for the Hugo Awards, but never tried reading anything. This one is ideal, as it is a collection of shorter novellas.
Fruit
Today I said: "Cherries are the best fruit with the worst user interface". I love how they taste, but I'm always afraid to choke or break a teeth on the core, I find it annoying to dispose of the petioles, and so on. A colleague replied: "There's a XKCD for that! And he disagrees!". Indeed there is one!
PyData Berlin 2018
First Python conference I attend.
The venue is in the complex of Charité – Universitätsmedizin Berlin: Forum 3 is a nice building and has also some space outdoors (fortunately the conference days were blessed by sun and a nice temperature).
- First keynote was not strictly related to Python or data science/engineering. It was an extremely interesting, fun and in some moments moving account of the hacker scene in Romania before the collapse of Ceaușescu's regime in the eighties. The story of the COBRA was particularly interesting (COBRA is a Romanian clone of ZX Spectrum, the result of a remarkable process of reverse-engineering, glorious stubborness and sometimes not-strictly-legal work-arounds).
- Next I attented Five things I learned from turning research papers into industry prototypes. A practical collection of advices if you are tasked with the mission of converting some "theory" from a paper into something executable. Apparently a problem the audience could relate to a great deal. You can find the slides here.
- Simple diagrams of convoluted neural networks seemed interesting, but unfortunately the presentation was hard to understand to my ears. Anyway, I managed to extract some value from it, mostly because the arguments led me to think about the general problem of devising a notation for expressing and describing a complex system (like a NN): it should make the reader able to follow the process step by step, it should make it easier to spot errors in the system, it should adhere consistently to the metaphor –if any– it decides to follow, it should pay attention to representing clearly what and how it's combined in the various phases of the process, and it should be dynamic (so apparently trying to represent neural networks using a static diagram is a lost cause?). The speaker said that the baseline is currently very low, and there's much space for improvement. The slides.
- Compared to the previous talk, Launch Jupyter to the Cloud: an example of using Docker and Terraform was very basic but very well presented. The lesson is you can use Terraform and Docker to completely describe (thus making it really reproducible) the entire configuration needed for an experiment (being it some data analysis task, a Jupyter notebook, things like that). The slides.
- I was particularly excited about the talk coming after the lunch break: Let's SQL Like It's (NOT) 1992! The main point of the speaker is that writing SQL is usually a skill one learns in college, then it's only rarely refreshed and kept up to date with the improvements to the standard. Also, SQL is frequently thought only as a query language, but it actually includes a data modeling language and a data definition language. The presentation was compelling and well delivered (it was actually a live coding session), but unfortunately James run out of time and had to stop abruptly and pass the podium to the next speaker before arriving at the most interesting parts of his talk. He promised to put the code on github. Besides a couple of idioms I didn't see before the talk, I discovered a seemingly useful extension for PostgreSQL, allowing users to implement bitemporal tables automatically (so that it's possible to have usual CRUD primitives, and still be able to reconstruct the state of the dataset at any given time).
- Next talk was A/B testing at Zalando: concepts and tools. A researcher from Zalando illustrated the tools (and the mindset) they adopted for conducting A/B tests. An endevour they took very seriously, apparently, as they dedicated 3 BE Engs + 3 FE Engs + 4 Researchers + 3 Product managers = 13 persons to it. They developed an internal tool called Octopus and released a OS Python library called ExPan for statistical analysis of randomised control trials. Highlights: one of the attendees asked what are common pitfalls when developing A/B tests. According to the speaker, one is testing too many variables at once (he said they're developing techniques to automatically detect variable "interference" in A/B experiments, such as frontend variations that can reciprocally hinder each other). Another common error is stopping the experiment too early (for example because management wants answers faster), leading to results that have no statistical relevance. He also stressed the point that stats and probability form only half of the picture: business stakeholders need to be involved from the very beginning (e.g. How much running an experiment cost?)
- Frankly, I chose next talk because I had headache, the other ones in this time slot seemed a bit above my head so I chose something simple: Solving very simple substitution ciphers algorithmically. It was about a toy problem (automatically decyphering mono-alphabetic substitution codes) so nothing new, but what I liked very much is that the speaker was a mathematician, and it was a pleasure following the terse, ordinate and precise explanation ("Let me first name and define a few things").
- The second keynote of the first day was about GDPR. It was a nice round up from the point of view of the legislator, explaining the principles (old and new) underlying the regulation. The juicy part came during the Q&A afterwards, according to me. First question was about a practical problem that might rise in the context of ML: what if some data a user decided to let the controller store is used to train a model, and then the same user asked for that data to be deleted? Is the model still valid? The speaker explained this is out of the scope by GDPR, it's an open question and she would be interested in reading a paper about that if someone would bother to write one. Second question was a bit of a critique: GDPR is endangering small startups and grassroot association that don't have the resources to implement what's needed for complying with the regulation: the speaker said it's a common problem and added that in her opinion the time (two years, more or less) we had to prepare for GDPR was not very well spent: we should have a platform allowing anyone to comply with GDPR using ready tools. We're not there yet.
- Last of the first day was the lighting talks session. I particularly like this formula: very brief (5 minutes) but intense talks about various topics, useful for those that had no time to prepare a full fledged about their idea. The most interesting was the "Don't trust your data" talk: a Phd student discovered a dataset about chemical compound skin penetration, used since the 60s is incomplete, yet used over time in many research endevours (such as training 20+ ML models). He went back to the original papers illustrating the dataset, discovered many more features were available, and published a new refined dataset. Certainly a lesson in questioning your input. End of first day.
- Second day opened with a keynote: Fairness and Diversity in Online Social Systems.
- Next, mobile.de (an Ebay company) presented the architecture and the tools they use to offer their users a personalized web experience, and specifically to infer future users' behaviour using a stream of events describing their usage of the website. They started using Hive (with Jinja2 to generate SQL queries) but then switched to (Py)Spark, gaining a 5x time improvement and, according to their judgement, a much easier system to understand. They didn't publish the slides but I found some pointers on one of the speakers' personal website: “Which car fits my life?” - mobile.de’s approach to recommendations.
In Going Full Stack with Data Science: Using Technical Readiness Level to Guide Data Science Outcomes Emily Gorcenski suggested we could use NASA's TRL (a scale used by engineers to measure progress of technology) adapting it into a "Data Science Readiness Levels" scale. Here the original scale, with a possible translation for software products and for data science projects.
TRL Product Data Science Basic principles observed Need or shortcoming identified Algorithm design & development Technology concept formulated Technology concept formulated Data explored and described Experimental proof of concept Tests written Experimental proof of concept Technology validated in lab Tests passing on dev machines Algorithm validated against sample data Technology validated in relevant environment Tests passing in develop Algorithm validated against production data Technology demonstrated in relevant environment In QA Algorithm integrated in develop Prototype demonstrated in relavant env. Beta version in limited staging Prototype demostrated in operational env. System complete and qualified QA passed and ready for staging System complete and qualified System proven in operational env. System running in production System proven in operational env. She proposed the idea of "full-stack teams" (opposed to full-stack devs, unrealistic if one has to take seriously the amount of knowledge modern system engineering encompasses), and the fact that data science / data analysis is inseparable from the other facets of a software project, since its inception.
- In Data versioning in machine learning projects Dmitry Petrov started from what I think is a very common problem: we have good tools to manage code versioning, but the same can't be said about versioning data. More generally, he stated that while hardware development has a well established methodology (Waterfall), and software development has one as well (Agile/Scrum), the same can't be said for data related projects. He presented a tool he's developing called DVC, an extension to git (similar to git-annex in some aspects) specifically designed for managing large volumes of data.
- Big Data Systems Performance: The Little Shop of Horrors by Jens Dittrich was in large part a tirade against the over-hyped terms like "Big Data" &co, that often bring more confusion than clarity when it comes to evaluate a solution for a data related problem. This lack of clarity hinders reaching an efficient solution, because of the mix of three "dimensions" that should instead be orthogonal (as the name Dittrich chose suggests): 1. fancy sounding buzzwords, 2. technical principles and patterns, 3. software platforms. He dismissed the first as good only for marketing (he apparently had a bad opinion about marketing), he said being familiar with 3 is important, but even more important is knowing very well 2, because those principles are ubiquitous and more solid. He brought a real life example, where he obtained a 10000x speed improvement applying different patterns and tools from the already existing solution.
First experiences with Python
At the new job I use Python for my programming tasks. Currently developing some data related stuff (ETL and reporting) and a web service, trying to organize the stuff I write so that it can be used by other members of the team for other projects. I will register a few impressions:
- Overall, I like the syntax. More specifically, I like the fact there are very few principles that uniformly apply in many situations. Most of the time I can "invent" the way something has to be written and it usually turns out as the right form.
- I like the ecosystem I've seen so far: pandas is a great tool, for example. I'm struggling with SQLAlchemy, but I never quite liked ORMs anyway.
- I am trying to follow PEP8, even if I have quite different ideas at least about aestethics in code (first time I run pylint on a script I scored -8.61/10).
- I didn't quite get yet the way modules are organized on the file system.
- I feel the documentation lacks regularity and completeness. I can find a lot of tutorials about any topic, but I still could not find a systematic source to use as a reference.
Update
Speaking of great tools in the Python ecosystem, I just discovered Jupyter received the ACM Software System Award. Congratulations!
eyebrowse
I started using eyebrowse more systematically. I tend to have multiple frames scattered around my xmonad workspaces, but I usually also have a workspace exclusively devoted to a fullscreen Emacs frame, and there I usually work on different projects, that require different windows configurations. So eyebrowse is useful. To be able to switch more confortably from a configuration to another, I added this little piece of code to my setup:
(loop for i from 1 upto 9
do (define-key eyebrowse-mode-map
(kbd (format "M-%d" i))
`(lambda ()
(interactive)
(eyebrowse-switch-to-window-config ,i))))
Code to read
I opened a new repository on github. It's called code-to-read, an
attempt to collect and organize links to code bases particularly good
for a human to read.
Haskell Day in Rome


Yesterday I spent the entire day in Rome to attend another Haskell meeting. It's been quite a productive and interesting event: as usual, instead of talks we had impromptu groups engaged in different practical projects. Yesterday, the majority of people followed a beginners course. In my case, I showed my Wiz project to some more experienced programmers, receiving a great deal of observations, questions and suggestions. Other remarks: I saw a "Frankenpad" and learned some details about it; I showed my mechanical keyboards to other aficionados; I unexpectedly received a bottle of Rohrer & Klingner Leipziger Schwarz fountain pen ink (thank you!).
"The right thing should be easier to do"
I register here a series of tweets I already posted, for further ruminations.
One nice thing about Lisp and image based dev environments is that they make the act of exploring easier and more frictionless. This means producing something working is easier, when you're learning a new API or technology. On the other hand they make easier also to transform a crack-fueled idea into something deceitfully working, especially if you don't know well the domain. Thus breaking the rule "Right things should be easier to do", I guess.
August 2017
I spent the entire month in Berlin, half telecommuting, half being my summer vacations. So, I had some free time I spent in many ways, in particular:
- Riding bike. Berlin is a very nice city to visit with a bike. Most of the streets have room dedicated to cyclists. Gardens and parks are a few minutes away, wherever you are. I guess the average velocity of the bikers is higher compared to Italy. Average attention and respect is higher too.
- Programming
- Some progress with my Scheme interpreter, the environment model is kind of working (enabling features like closures), but I'm still having problems with quoting (this is what prevents me from pushing lastest changed to a public repository).
- Minor fiddling with Lisp, specifically using CEPL (I have I rather ambitious project idea).
- Reading
- Designing Data-Intensive Applications by Martin Kleppmann
- The Rise and Fall of Dodo by by Nicole Galland and Neal Stephenson
- Winter of the World by Ken Follett. A friend recommended the Century Trilogy to me (this is book two). Not my usual genre, but it flows easily and as I developed an attachment for some of the characters, I want to know what is going to happen to them.
- Painting
- I was scouting the web for technical conferences to attend, but I found instead a watercolor course for beginners. One could even register for just one lesson. I ended up doing five (7.5 hours total). It was very fun, interesting and useful, absolutely worth the money. And I made some new friends in the process. Call it serendipity.
- Playing
- See below about The Swapper
The Swapper

Decided to download a new game from Steam, The Swapper. Interesting game mechanic, and daunting sci-fi setting.
When did you start using Emacs?
When did you start using Emacs?
Noticed this Reddit thread in one of Sacha Chua's Emacs News posts, and wondered what I could answer.
~/.emacs.d (master) $ git log --reverse --pretty=format:%ai | head -n 1
2014-05-23 10:29:04 +0200
I didn't realize it's been 3 years already since I started using Emacs.
Wacom tablet
Quite surprisingly, the rotation property is a property of the stylus and the eraser, not of the pad.
$ xsetwacom --set "Wacom Bamboo 16FG 4x5 Pen stylus" Rotate half
$ xsetwacom --set "Wacom Bamboo 16FG 4x5 Pen eraser" Rotate half
Games
I've been playing more than the usual, recently:
- The Last Door (I played the Android version) - This is a classic point-and-click adventure. Rather simple, but the plot -a homage to Lovecraft's and Poe's horror tales- is interesting. Special mention for the original soundtrack, a real plus in setting the mood. The graphics is intentionally low-res and pixelated, an odd choice that surprisingly played well on a game of this type: I guess it is because the player's mind has to convert the limited detail the images offer into actionable information, thus staying more focused. In practice, I ended up being immersed into the game reality, and that made the scary moments (some of them really upsetting) more effective. Recommended.
- SIM (Sara is missing) (I played the Android version) - In this game of interactive fiction Sara is missing and you find her smartphone. You're supposed to rescue her, looking for clues in her messages, emails and whatnot, with the aid of Iris, an artificial intelligent system running on her phone. The game is very simple and the player is merely instrumental in letting the story unfold. There are a few scary moments, but in retrospective they were more about how the message was delivered, rather than the message itself. To sum up, the game mechanism is interesting but I would have appreciated a more complex plot.
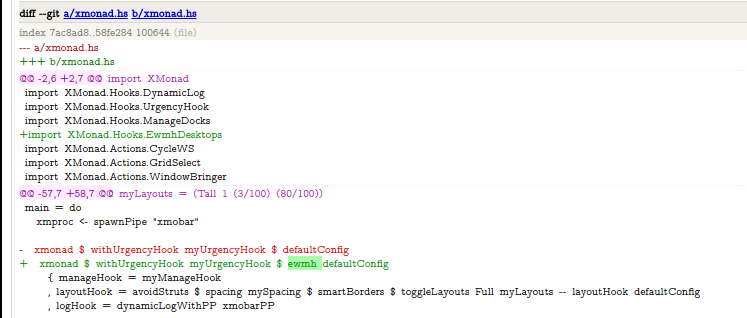
xmonad + Libreoffice problems
Apparently I fixed the pesky problems I had with xmonad + Libreoffice.
Status update
Some days off, not very much done. Somehow relevant in the context of this stream:
- Writing some simple Common Lisp, for exercise. The Wireworld simulator and editor –which has some significance per se besides being interesting as a CL exercise– is on pause (while I try to figure out Lispbuilder-sdl's ways of treating surfaces), and I'm now on something simpler. It's a Sudoku solver assistant. It's not clear to me what the scope of the project will be, however I'm discovering handy techniques and tools useful for a "real" system: for example I borrowed from scmutils the idea of using TeX to obtain a representation of the Sudoku problem (it's faster than I initially thought).
- Reading Seveneves by Neal Stephenson. I hope to write something more substantial as I reach its end.
New site structure
I just published a restructuring of my website. Content is more or less the same. Main difference is I ditched the blog: I discovered blogging (I mean, organizing the stuff I publish as distinct articles ordered in time) is not for me. I'm more comfortable dedicating a page to each project I'm following, and keep updating the page as the project proceeds.
Ditching the blog also means I'm now using one tool only for all the editing and publishing.
Things to do:
- testing
- implement some sort of feed for the updates
- re-linking minor stuff that has not yet a place in the new structure
Switched to Ubuntu Xenial Xerus
Better hardware support with less work for me (the Broadcom Wifi chip has been recognized with no problems).
Yay! New laptop
Now some work to make it work like I want (it comes with Windows 10 installed but I want a GNU/Linux system on it. So far I've only tried a live distro to check hardware support. As I expected, it's going to need some work to make the wifi chipset work properly).
Update
Linux installed. First update from the new environment!
Spoiled by xmonad
I'm doing some experiments with xmonad and I particularly like its
mod-Space key combination to switch the window layout in a
workspace. Is there something similar for Emacs?
This is similar to what I want: ThreeWindows
Update
I ended up doing this (the entire code is here: larsen-functions.el)
(defvar *larsen/split-layout-type* t)
(defun toggle-split-layout ()
(interactive)
(progn (change-split-type-2 *larsen/split-layout-type*)
(if *larsen/split-layout-type*
(setq *larsen/split-layout-type* nil)
(setq *larsen/split-layout-type* t))))
(global-set-key (kbd "M-<f1>") 'toggle-split-layout)
Trying to configure ox-rss.el
I'm trying to properly configure ox-rss.el to produce a feed for this stream.
TMK firmware
Trying the tmk firmare on the Atreus. The feature list is very interesting, but it's not clear to me if it's all appliable to the specific hardware I'm using.
Anachronistic computing
Yay! The laptop I recently bought for a ridiculously low price is eventually working like I want.
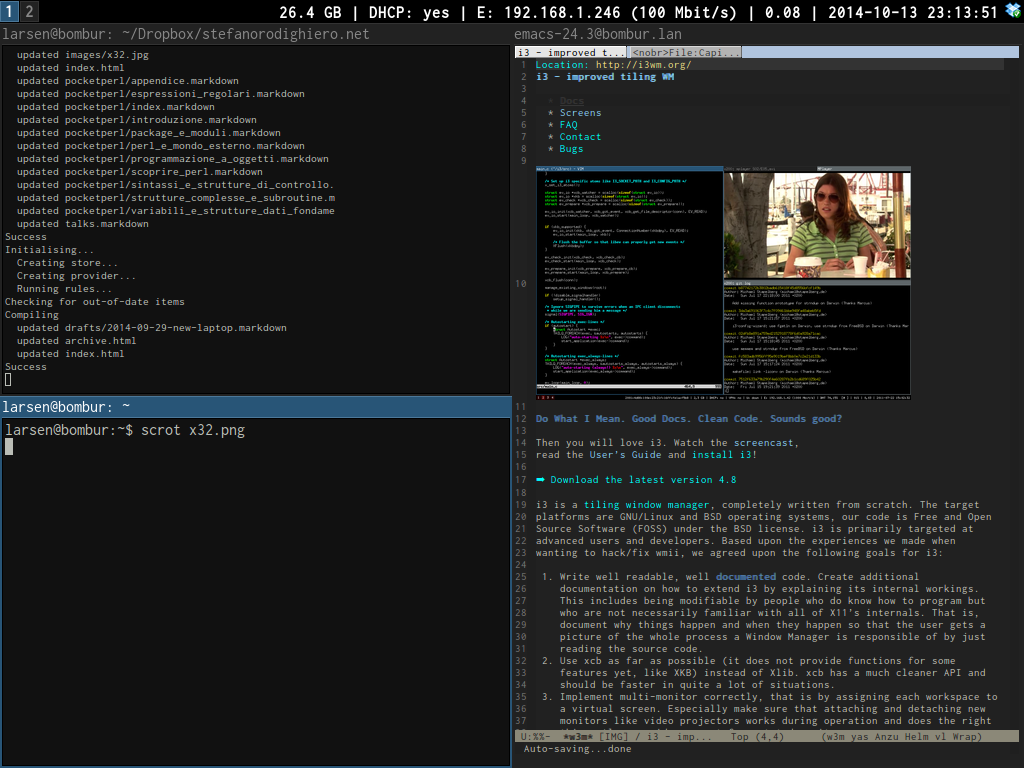 First its characteristics:
First its characteristics:
| CPU | Intel Pentium M (Dothan) |
| RAM | 512MB |
| HDD | 40GB 2.5" PATA |
| Display | 12.1" TFT with 1024x768 resolution |
It is a IBM Thinkpad X32. A good news is it sports one of the best keyboards one can find on a laptop (and I was lucky enough to find the GB layout). I found it at an electronic fair I recently visited, and grabbed it without much thinking from the pile (literally) where it layed together with some of its twins.
I think it's remarkable that such an old piece of hardware can be a perfectly usable machine (at least for the way I'm used to work). All it takes is some attention to the software one chooses to install:
- Linux, obvious choice to revive old hardware (in this case, I had to recur to a non-PAE kernel due to the particular CPU architecture)
- i3, a lightweight tiling window manager
- Emacs 24.3, where I'm going to spend much of my time (w3m is a decent surrogate of a proper graphical browser for reading documentation)
- I'm even running Hakyll locally to prepare this post
2011 in books
Essays/Computer science/$work stuff
- Programming Pig
- Hadoop The definitive guide
- Cassandra: The definitive guide
- Data Analysis with Open Source Tools
In 2011 I started my adventures in the perilous lands of bigdata, so I've begun harvesting literature on the subject. Extremely interesting and relatively young field. I have an almost finished review of "Data Analysis with Open Source Tools" which I hope to publish soon.
Novels
My first encounter with Douglas Coupland. I particularly liked Microserfs, that somehow seemed to be speaking directly to me. Perhaps not for everybody.
Five minutes after Games of Thrones s01e01 I realized I couldn't wait an entire week to know the rest of the story. Still entertaining, after ~3000 pages and already in the fourth book.
I'm a hardcore Neal Stephenson fan. I also have Anathem in my stack, but I decided to read Reamde first, because it seemed less dense. It was, and also more fast-paced than usual.
Kindle first impressions
I just unboxed my Kindle. I played with it for a few hours only, but I'm satisfied with the choice so far.
First of all, to the zealots that may happen to read this article and feel compelled to whine on "scent of paper" and other oddities: I'm not planning the disposal of all my "real" books, neither I'm considering buying only digital contents from now on.
I decided to buy an ebook reader because I wanted to see on my own what can be done with this technology, which I consider immature and yet to be completely exploited. I think I am an early adopter, even if Amazon Kindle and its competitors hit the market several years ago.
Also, I think having an ebook reader is nowadays the most practical solution to the eternal problem "What books should I bring with me during the journey?". Being able to answer "All!" is a wild dream that comes true (but I understand this can be a problem as well).
Anyway, here a few impressions from a very very beginner.
- The device itself looks beautiful. It's not heavy and it seems prolongated use will not be tiring. On the other hand, I have the impression it's not particularly sturdy. Again, this is something I can say only in a few months (or in a few hundreds kilometers).
- I think the slogan "it's like paper" is inaccurate. Whatever appears on the screen seems printed, but it does not recall paper to me. Besides that, fonts are very crisp and readable, so Kindle hits on the spot for what is supposed to be its main use.
- I am positively surprised by the refresh delay. Maybe because I expected it to be even worse, I think it's bearable, at least for the kind of books you read cover to cover in a sequential fashion. In other words, good for novels, articles and stuff like that; maybe not practical for manuals, documentation… in general, things you want to study, or browse randomly.
- I suspect I will eventually feel hampered by the position of buttons on the device. Anyway, this can't be but a speculation.
- I'm currently at my parents' place, and there are problems with the Internet connection, so I couldn't try its wifi capabilities yet. A pity: one of the things I was more eager to try was Kindle's use in conjunction with Instapaper.
- Ah, the screensavers are wonderful!